

RESUMEN V.1
INTRODUCCIÓN A LA LECTURA
Hace unos 5.000 años que se inventó el lenguaje escrito y sólo dos siglos desde que se empezó a usar de manera masiva, en la actualidad la mayor parte de la información nos llega a través de los textos escritos. Al no estar programado en el cerebro, el lenguaje escrito requiere un aprendizaje sistemático de varios años hasta conseguir leer de una manera fluida y automática. Cada vez que una palabra o frase aparece ante nuestros ojos no podemos evitar leerla. En consecuencia, la lectura se ha convertido, junto con la comprensión oral, en un tema central de la psicología del lenguaje.
La lectura requiere unos procesos similares a los que empleamos en el lenguaje oral, ya que el objetivo que persigue es el mismo: comprender un mensaje a partir de unos estímulos físicos que llegan a nuestros sentidos. La diferencia radica en que en el lenguaje oral esos estÍmulos son ondas sonoras que llegan a nuestros oídos, y en el lenguaje escrito, son signos en el papel o en la pantalla que se proyectan sobre nuestros ojos. De hecho, mientras que en el lenguaje oral los fonemas que forman las palabras van llegando a nuestros oídos de manera sucesiva y desaparecen inmediatamente, en el lenguaje escrito las letras que forman las palabras aparecen todas a la vez y permanecen en nuestro campo visual durante todo el tiempo que queramos, lo que nos permite volver a leer una palabra si no estamos seguros de haberlo hecho bien. A partir de los fonemas en el lenguaje oral y de las letras en el lenguaje escrito reconocemos las palabras, algo fundamental para entender el mensaje.
En el lenguaje oral, la variable más determinante de la rapidez en el reconocimiento de las palabras es el punto de unicidad. En cambio, en la lectura, la palabra aparece completa ante nuestra vista, por lo que el punto de unicidad tiene poca importancia, y menos aún en los lectores expertos que identifican rodas las letras en paralelo. En el reconocimiento de palabras escritas, las variables más influyentes son la frecuencia de uso y la edad de adquisición. La prosodia y los gestos del hablante son componentes importantes en la comprensión oral, aparte de que hablante y oyente están haciendo referencia constantemente al contexto.
PERCEPCIÓN DE LA INFORMACIÓN ESCRITA
| Dehaene (2009). «disfrutamos de la lectura de Nabokov y Shakespeare usando un cerebro de primate diseñado originalmente para vivir en la sabana africana» (Reading in the brain, p. 4). |
El lenguaje escrito es una adquisición reciente, por lo que todavía no ha transcurrido tiempo suficiente para que pueda programarse genéticamente en nuestros cerebros.
Movimientos sacádicos y fijaciones
| McConkie y Rayner (1976) demostraron que, durante una fijación, el lector se sirve de la información parafoveal distante, es decir, la información borrosa que percibe por el «rabillo del ojo», para decidir el lugar del texto adonde dará el salto para la próxima fijación. |
| Rayner y McConkie (1976). Probablemente las personas que más han investigado sobre los movimientos oculares durante la lectura, han encontrado saltos de sólo dos caracteres y saltos de hasta 18 caracteres en sólo unas pocas líneas de separación. Como las fijaciones, los movimientos sacádicos están determinados por las variables del texto (complejidad, longitud de las palabras, frecuencia, etc.) y las características del lector. Pero, por término medio, durante la lectura, nuestros ojos pasan el 90 % del tiempo percibiendo las palabras y el 10 % cambiando hacia nueva información. |
| Rayner et al. (1981). Comprobaron que de los 200-250 ms que normalmente dura cada fijación, la extracción de la información visual sólo requiere de los primeros 50 ms. En un experimento presentaban frases para que los participantes las leyesen y, cuando llevaban un pequeño tiempo de fijación, interponían un estímulo que impedía seguir leyendo. Cuando la interposición se producía antes de los primeros 50 ms, los sujetos no eran capaces de leer la información que tenían delante de sus ojos, pero si se producía pasado ese tiempo la leían sin dificultad. |
| Just y Carpenter (1987). Los niños disléxicos realizan muchas regresiones. Normalmente las regresiones suelen ser cortas y dirigirse a zonas próximas, pero a veces se producen saltos que llegan varias líneas atrás. |
de la palabra a cada hemisferio.
Cuando leemos, colocamos el texto frente a nuestros ojos, pero aunque nuestro campo visual es muy amplio, ya que abarca casi 180°, realmente nuestra agudeza visual se limita a una franja muy pequeña, la zona de la fóvea en el centro de la retina. Esta zona ocupa sólo 3°, lo cual significa que únicamente podemos ver unas 10 o 12 letras, es decir, dos palabras cortas (p. ej., «puto Covid») o una palabra larga («putamierda»). Para poder ver las siguientes palabras nuestros ojos tienen que desplazarse a una nueva posición, pero no lo hacen de una manera suave y progresiva, sino mediante saltos bruscos denominados movimientos sacádicos.
En definitiva, cuando leemos, nuestros ojos se fijan en una zona del texto (generalmente se comienza por la parte de arriba a la izquierda), nueva fijación y nuevo movimiento sacádico hasta llegar al extremo derecho de la página. Durante los períodos de fijación extraemos la información de las palabras y accedemos a su significado y pronunciación, y durante los movimientos sacádicos desplazamos nuestra atención a la siguiente parte del texto. Los períodos de fijación dependen mucho del lector y del tipo de texto, pero el promedio es de unos 200 o 250 ms. Con textos difíciles, textos formados por palabras de baja frecuencia o textos importantes, los períodos de fijación son mayores. El comienzo de un nuevo tema también supone un incremento en los tiempos de fijación. En cuanto a los movimientos sacádicos, el tiempo medio de duración es de unos 20 o 40 ms, aunque también presenta variaciones. La amplitud media de los desplazamientos es de unos 8 o 10 caracteres (contando letras y separaciones entre letras), aunque también existe una gran variabilidad en los saltos sacádicos.
Una característica importante de los movimientos sacádicos es que una vez que inician un movimiento, ya no es posible corregirlos. En consecuencia, la elección del próximo punto de fijación tiene que ser realizada antes de iniciar el movimiento. ¿Cómo se decide entonces dónde deben aterrizar los ojos para iniciar la siguiente fijación? McConkie y Rayner (1976) demostraron que, durante una fijación, el lector se sirve de la información parafoveal distante, es decir, la información borrosa que percibe por el «rabillo del ojo», para decidir el lugar del texto adonde dará el salto para la próxima fijación. Por otra parte, en la propia fijación hay un sesgo hacia la derecha, debido a que la lectura va de izquierda a derecha (en nuestro sistema alfabético) de modo que nuestros ojos van buscando información hacia la derecha. Por eso, de las 10 o 12 letras, aproximadamente, que fijan nuestros ojos, no hay 5 o 6 para cada lado, sino 3 o 4 hacia la izquierda y 7 u 8 hacia la derecha.
El sistema cognitivo necesita un tiempo para acceder aLsignificado y pronunciación de las palabras, y mientras no termina de hacer ese trabajo no recoge más información. Por esa razón, al final de las frases las fijaciones duran más, porque se está procesando la frase completa. Esta coordinación ojo-mente es la que marca la velocidad lectora y la que hace que nuestros ojos no puedan avanzar más rápido de lo que la mente les permite.
identificación de las letras
| Cattell. Trabajos pioneros de Cattell de finales del siglo XIX sobre el reconocimiento de palabras presentadas durante un tiempo breve en el taquistoscopio. Cattell comprobó que los sujetos tenían más dificultades para identificar letras cuando se presentaban aisladas que cuando formaban parte de una palabra. |
| Pillsbury. Presentaba a sus participantes durante un breve tiempo palabras que tenían una letra borrosa por llevar encima una «X» para que las identificasen. A pesar de la «X», los individuos identificaban perfectamente las palabras y, además, la mayor parte de las veces no eran conscientes de la existencia de la «X». Sus resultados apoyan la tesis de Cattell. |
| Reicher (1969). Propuso un nuevo paradigma en el que también presentaba palabras durante una breve exposición, pero la tarea de los participantes era decidir entre dos letras que se presentaban a continuación si una de ellas aparecía en una posición determinada de la palabra anterior. Pero esas dos letras se seleccionaban cuidando que no pudieran ser adivinadas. Por ejemplo, si se presentaba la palabra «abril», las letras sobre las que los sujetos tenían que responder eran «r» y «i» en la última posición, dado que en ambos casos se forma una palabra (abril/abrir), por lo que no queda espacio para la adivinación. La ejecución en esta condición se comparaba con otra en la que se presentaban varias letras de manera aleatoria (p. ej., «airbl») . Aun con este control experimental, los resultados siguieron siendo mejores para las palabras que para la serie de letras, lo que seguía apoyando el denominado «efecto de superioridad de las palabras». |
| Johnson (1975). Utilizó una tarea en la que los participantes tenían que emparejar letras aisladas o palabras completas. Los sujetos tardaban aproximadamente el mismo tiempo en decidir si una palabra era igual a otra presentada previamente que en decidir si una letra era igual a otra también presentada previamente. Por consiguiente, Johnson también concluyó que no es necesario identificar las letras para reconocer las palabras. |
| McConkie y Zola (1979). En un experimento, presentaban oraciones en una pantalla en las que las palabras tenían las letras alternadas entre mayúsculas y minúsculas: «LaStRoPaSeNeMiGaSa VaNzAbAnAgRaNvElOcldAd . . . » Cuando los sujetos realizaban los movimientos sacádicos correspondientes, cambiaban los tipos de letras, de modo que las que estaban en mayúscula pasaban a minúscula y viceversa: «lAs TrOpAsEnEmlgAsAvAnZaBaNaGrAnVeLoCiDaD . . . » Los investigadores comprobaron que esos cambios no producían en los sujetos dificultad adicional alguna durante la lectura, ya que la duración de las fijaciones y la longitud de los movimientos sacádicos no eran diferentes a la condición en la que se conservaba el mismo tipo de letra. |
| Cuetos (2008). El sistema de plantillas no encaja con el funcionamiento cerebral responsable de la lectura. |
Durante las décadas de los setenta y los ochenta del siglo XX tuvieron gran influencia los métodos globales que enseñaban a leer a partir de la palabra completa, más que de la letra o la sílaba. Si el reconocimiento de las palabras se hace de manera global, parece lógico que se enseñe a leer mediante palabras completas, y no con partes de la palabra. Sin embargo, investigaciones posteriores con experimentos muy controlados desde el punto de vista metodológico mostraron que no es posible reconocer las palabras si no se identifican previamente las letras componentes, y que los resultados sobre el efecto de superioridad de las palabras no eran más que artefactos experimentales. La hipótesis del reconocimiento global no tiene una respuesta clara a la pregunta de qué es exactamente lo que nos permite reconocer las palabras, si no son las letras individuales.
Una de las primeras tareas que nuestro sistema lector realiza en los milisegundos que dura la fijación
es la identificación de las letras.En los años setenta del siglo pasado se planteó la hipótesis de plantillas para explicar el reconocimiento de las letras. Según esta hipótesis, los lectores disponemos de representaciones con las formas de cada letra, una especie de plantillas con las que vamos comparando las letras que vemos escritas. Esta hipótesis es intuitiva, pero tiene el inconveniente de que no nos bastan 27 plantillas -una para cada letra-, ya que las letras pueden escribirse de maneras muy diferentes, en mayúscula, minúscula, script, cursiva, etc. (f, F, f, F, F, etc.), por lo que necesitaríamos multitud de plantillas para poder reconocer cada una de las letras. Por otra parte, este sistema de plantillas no encaja con el funcionamiento cerebral responsable de la lectura (Cuetos, 2008).
Actualmente tiene más defensores la hipótesis de rasgos, según la cual cada letra se define por una serie de rasgos, de manera que, cuando el sistema detecta determinados rasgos, deduce de qué letra se trata. Así, por ejemplo, la detección de los rasgos línea vertical y dos líneas horizontales, una arriba y otra en el medio lleva a la letra «f» ; línea vertical y punto arriba, a la letra «i», etc. Esta hipótesis se ajusta mejor al funcionamiento cerebral, ya que nuestro sistema visual cuenta con unos detectores de rasgos (células simples y complejas en el área visual primaria) que se activan ante estos rasgos que definen las letras (línea vertical, línea horizontal, línea inclinada, círculo, etc.).
RECONOCIMIENTO DE PALABRAS ESCRITAS
El reconocimiento de palabras es el proceso fundamental de la lectura, puesto que implica nada menos que extraer el significado y la pronunciación de los signos que hay escritos sobre el papel o la pantalla. Algo que sorprende enormemente es la rapidez con que reconocemos las palabras escritas. En cuanto vemos una palabra ante nuestros ojos nos da la sensación de que instantáneamente recuperamos su significado y su pronunciación. El proceso de reconocimiento de palabras escritas mejora con el aprendizaje, puesto que la lectura, al contrario que el lenguaje oral, requiere una enseñanza sistemática y continuada en el tiempo, de manera que en los primeros años los niños tardan varios segundos en acceder al significado y a la pronunciación de las palabras escritas, pero a medida que van adquiriendo fluidez los procesos se automatizan y los tiempos se acortan, hasta el punto que los lectores expertos no pueden evitar leer las palabras que aparecen en su campo visual, incluso aunque intenten no leerlas. Se han utilizado muchas metodologías diferentes para investigar los procesos de reconocimiento de las palabras escritas, principalmente basadas en los tiempos de reacción, aunque también en los tiempos de exposición y de seguimiento de los movimientos oculares y las técnicas electroflsiológicas.
Metodología
Para el reconocimiento de las palabras escritas contamos también con un amplio número de técnicas, algunas de ellas se describen a continuación.
Umbral de reconocimiento
Consiste en la identificación de palabras que se presentan de forma muy breve en una pantalla. Es la tarea más tradicional de todas y su uso se inició en el siglo XIX. Entonces se utilizaba el taquistoscopio. Hoy esta metodología se aplica a través de los ordenadores, que, además de su versatilidad en la presentación de los estímulos, tienen la ventaja de registrar las respuestas.

Las variables independientes pueden ser muy diversas, dependiendo del objetivo de cada experimento. Así, si se desea averiguar si se identifican mejor las palabras cortas que las largas, se usará como variable independiente la longitud de las palabras, seleccionando estímulos cortos y largos para comparar los resultados. Un inconveniente general del método de identificación es que no obliga al sujeto a responder de forma rápida, lo cual puede permitir la intervención de otro tipo de procesos posléxicos (estrategias de adivinación, etc.) distintos de los que se pretenden estudiar.
Decisión léxica visual
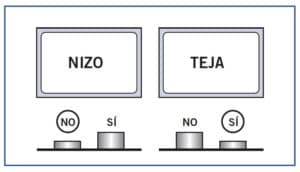
de palabras. Ante la presentación de cada estímulo, el participante debe pulsar lo más rápido posible uno de dos botones: sí (palabra) o no [no-palabra).
| Rubenstein, Garfield y Millikanen (1970). Emplearon por primera vez la tarea de la decisión léxica visual. |
El participante debe decidir lo más rápidamente posible si una serie de letras es, o no, una palabra de su idioma pulsando uno de dos botones o teclas. La mitad de los estímulos suelen ser palabras y la otra mitad no-palabras. Es la tarea más utilizada para investigar el reconocimiento visual de palabras, ya que permite manipular de una manera fácil las características de las palabras (longitud, frecuencia, complejidad morfológica, etc.) y medir el tiempo que transcurre desde que aparece el estímulo en la pantalla hasta que el sujeto pulsa una de las teclas.
Lectura en voz alta
| Cueros y Barbón (2006). El tiempo medio de lectura de las palabras en la tarea de Lectura en voz alta se sitúa en torno a los 500 ms. |
En esta tarea no hace falta tomar una decisión sobre el estímulo. Simplemente se presentan palabras en la pantalla del ordenador para que el participante las pronuncie en voz alta, lo más rápido posible. De nuevo, la variable dependiente es el tiempo de reacción que transcurre desde la presentación del estímulo hasta el inicio de la respuesta vocal. Su registro lo realiza el ordenador gracias a una llave vocal, dispositivo que se activa ante la llegada de la voz.
Es importante no olvidar que el tiempo registrado no incluye el tiempo que consume la propia pronunciación. El supuesto básico que subyace en esta técnica es que el tiempo necesario para iniciar la pronunciación de una palabra depende de su accesibilidad o disponibilidad en el léxico mental. Cuanto más accesible es la unidad léxica, antes comenzará la respuesta verbal.
Categorización semántica
En la tarea de categorización semántica se presentan palabras pertenecientes a dos categorías diferentes (p. ej., animales domésticos frente a animales salvajes) para que los individuos respondan pulsando uno de dos botones o teclas a cuál de las dos categorías pertenecen. Esta tarea mide el acceso al sistema semántico, pues se supone que para responder a qué categoría pertenece cada palabra el sujeto tiene que acceder a su significado. Al igual que en la decisión léxica, se mide el tiempo desde que se presenta la palabra hasta que el individuo responde pulsando una de las dos teclas.
Movimientos oculares
| Raymond Dodge hacia el año 1900 inventa la técnica de la reflexión corneana. |
Algunos experimentos no se limitan al simple seguimiento visual, sino que modifican, en tiempo real, el contenido de la pantalla dependiendo de la mirada del participante. La información más relevante que proporciona esta técnica es el lugar y el tiempo de fijación. Se parte del supuesto de que, cuanta más cantidad de procesamiento requiere una palabra, mayor será el tiempo de fijación sobre ella. Esta técnica tampoco exige decisiones conscientes, como en la tarea de decisión léxica, y su principal atractivo reside en
su validez ecológica, es decir, en el hecho de que la situación de laboratorio es semejante a la situación natural de lectura de un texto. Su principal inconveniente surge, precisamente, de su ventaja, puesto que en la medida en que se trabaja con textos, es difícil deslindar, a partir de los datos, los procesos de acceso léxico de otros procesos de orden superior.
Priming
| Meyer y Schvaneveldt (1971). Comprobaron que cuando una palabra va precedida de otra con significado relacionado (p. ej . , enfermera-DOCTOR), los tiempos de reconocimiento de la segunda disminuyen considerablemente. Desde entonces, numerosos experimentos con todas las técnicas (decisión léxica, lectura, etc.) han comprobado la robustez de este fenómeno. |
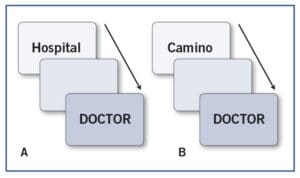
La técnica de priming se utiliza para estudiar el curso temporal del reconocimiento de las palabras. Consiste en la presentación de una palabra inmediatamente antes de la que el individuo tiene que reconocer, aunque en este caso las palabras se presentan de forma escrita. La palabra previa se denomina prime, y la que el individuo tiene que reconocer, target. En función de la relación entre el prime y el target y del tiempo de separación entre ambos (SOA), los tiempos de respuesta varían considerablemente. Dependiendo de la relación entre prime y target se distinguen varios tipos de priming.
El priming de repetición es aquel en el que se presenta la misma palabra como prime y target (p. ej., barco- BARCO). Los efectos de priming de repetición son muy potentes, posiblemente porque se produce activación a todos los niveles: ortográfico, fonológico y semántico. No obstante, el efecto es mayor en las palabras de baja frecuencia que en las de alta frecuencia, debido a que estas últimas se activan enseguida sin necesidad de ayuda. Esta interacción se conoce con el nombre de atenuación por la frecuencia. En el priming ortográfico o formal, el prime y el target comparten muchas letras, por lo que tienen un gran parecido ortográfico (p. ej ., carnero-CARTERO) . En el priming fonológico el parecido entre prime y target es en la pronunciación. En castellano, priming fonológico y priming ortográfico son prácticamente indistinguibles porque las palabras que se pronuncian de forma parecida también se escriben de manera parecida. En el priming semántico prime y target están relacionadas con respecto a su significado (p. ej ., perro-GATO).
En función del intervalo temporal entre el prime y el target (SOA), se distinguen dos tipos de priming (controlado y automático). En el priming controlado el intervalo temporal es superior a los 250 ms, por lo que los individuos ven perfectamente el prime, aunque no tengan que responder ante él, sino sólo al target. En el prime automático la separación es inferior a los 250 ms, por lo que los sujetos no tienen tiempo de llevar a cabo ninguna estrategia, y todos los efectos que se observen son producidos de manera automática. Hay incluso un tipo de priming, denominado priming enmascarado, en el que el prime se presenta durante un tiempo muy breve, en torno a los 50-75 ms y, además, es inmediatamente tapado por una máscara de signos para dificultar su percepción. En estos casos los participantes no son conscientes de la presencia del prime, pero aun así se observan efectos importantes sobre los tiempos de reconocimiento.
Se ha comprobado que el priming ortográfico ocurre en los primeros momentos del procesamiento; de hecho, sólo produce efectos facilitadores con SOA cortos, principalmente con el priming enmascarado. En cambio, el priming semántico se produce en momentos más avanzados y con cualquier intervalo. Esto significa que en los primeros milisegundos del procesamiento ya reconocemos las palabras, pero tardamos un poco más en acceder a su significado
Potenciales evocados
| Hauk y Pull-vermüller (2004). Estudiaron los efectos de la frecuencia y la longitud de las palabras en una tarea de decisión léxica, y encontraron que la longitud influía en una fase más temprana, en torno a los 125 ms, mientras que la frecuencia lo hacía hacia los 200 ms. |
| Cuetos et al. (2009). Investigaron la frecuencia y la edad de adquisición y comprobaron que la frecuencia producía cambios más tempranos que la edad de adquisición, en una tarea de lectura silenciosa, por lo que concluyeron que estas dos variables tienen efectos independientes y sobre distintos procesos (efectos léxicos en el caso de la frecuencia y semánticos en el caso de la edad de adquisición). |
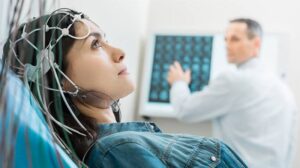
La técnica de potenciales evocados mide la actividad eléctrica cerebral a través de unos electrodos colocados sobre el cuero cabelludo de los participantes. Los potenciales evocados son una técnica muy útil para obtener información sobre el curso temporal del reconocimiento de palabras, porque proporciona datos sobre los cambios cerebrales milisegundo a milisegundo, es decir, tiene una gran resolución temporal. Algunas ondas se han asociado a determinados procesos:
- La onda N400 va asociada al procesamiento semántico.
- La onda N200 va asociada al procesamiento ortográfico.
- La onda N320 va asociada al procesamiento fonológico de las palabras.
Resultados
| Gough (1972). Los tiempos de lectura de una palabra se incrementan casi de manera lineal con su número de letras. Gough estimaba en unos 10-20 milisegundos por cada letra de más que tuviesen las palabras. |
| Swinney (1979). En un experimento ya clásico, presentaba oraciones en las que aparecía una palabra ambigua, como «plantas» en el siguiente ejemplo. El contexto podía ser neutro, ya que no indica si plantas se refiere a los pisos del edificio o a los vegetales o podía ser sesgado al hacer referencia clara a los vegetales. – Neutro: uno de los mayores problemas de los modernos edificios de oficinas es el de la limpieza, debido a la gran cantidad de plantas que tienen. – Sesgado: uno de los mayores problemas de los modernos edificios de oficinas es el de la limpieza, debido a la gran cantidad de hortensias, ficus y otras plantas que tienen. A continuación, los sujetos tenían que realizar una tarea de decisión léxica en la que se presentaban referencias a ambos significados, «pisos» y «flores», junto con otra palabra de control, por ejemplo, «libros». Swinney comprobó que cuando la palabra aparecía justo después del contexto sesgado, tanto la palabra relacionada «flores» como la no relacionada «pisos» se reconocían antes que la de control, pero cuando aparecía 700 ms más tarde sólo se producían tiempos cortos con la palabra relacionada. Esto significa que en los primeros milisegundos se activan todas las representaciones léxicas que corresponden a la palabra escrita, con independencia de que sean o no plausibles por su significado, aunque poco después ya sólo queda activada la correspondiente al significado. |
| de Vega et al. ( 1990). Comprobaron que, una vez eliminado el efecto de otras variables, el procesamiento de cada palabra estaba relacionado negativamente con las frecuencias posicionales de sus sílabas (es decir, su frecuencia de aparición en el idioma en determinadas posiciones dentro de la palabra), de manera que, paradójicamente, las palabras con sílabas muy frecuentes requerían mayores tiempos de lectura. |
| Carreiras, Álvarez y de Vega (1993). Empleando la tarea de decisión léxica constataron el efecto silábico inhibitorio: las latencias de las respuestas, una vez controladas otras variables potencialmente influyentes, eran más largas ante palabras con alta frecuencia silábica posicional que ante palabras con baja frecuencia silábica posicional, y este efecto era más pronunciado en las palabras de baja frecuencia léxica. Este efecto inhibitorio se interpreta, por lo general, en términos de competición entre unidades de representación léxica: si las sílabas son de alta frecuencia, activarán más unidades léxicas que las de baja frecuencia, y estas unidades competirán en el proceso de identificación de la palabra. |
| Seymour, Aro y Erskine (2003). Compararon el aprendizaje de la lectura de 14 idiomas europeos y constataron que los niños de sistemas ortográficos transparentes, como el griego, el castellano o el italiano, aprendían a leer mucho antes que los de idiomas opacos, como el danés o el inglés. Mientras que los niños griegos leían correctamente el 98 % de las palabras y el 92 % de las seudopalabras ya en el primer año de aprendizaje, y los españoles el 95 % y el 89 %, respectivamente, los escoceses sólo leían el 34 % de las palabras y el 29 % de las seudopalabras. |
| Domínguez, Alija, Rodríguez-Ferreiro y Cuetos (2010). En castellano son especialmente relevantes la frecuencia de sus sílabas y su complejidad morfológica, ya que se trata de un idioma con una estructura claramente silábica y una gran riqueza morfológica. Sin embargo, parecen tener efectos opuestos, dado que la frecuencia de las sílabas entorpece el reconocimiento de las palabras (a mayor frecuencia de las sílabas, mayores los tiempos de reacción), mientras que la frecuencia de los morfemas (especialmente los prefijos) lo favorece. |
Hoy se dispone de abundante información sobre las características de las palabras que determinan los tiempos que se tarda en acceder a su significado y/o pronunciación. Aunque las diferencias entre las distintas palabras son pequeñas (se trata de milisegundos, es decir, la milésima parte de un segundo), aparecen de manera constante y en la mayoría de las personas: tardamos unos milisegundos más en reconocer una palabra de ocho letras que una de seis.Tardamos unos milisegundos más en reconocer una palabra de baja frecuencia que otra de alta frecuencia, etc. El interés en estudiar los efectos que las diferentes variables tienen sobre los tiempos de reacción radica en que a través de esos efectos es posible inferir los procesos cognitivos que intervienen en la lectura en general y en cada situación particular.
Son muchas las variables que influyen sobre los tiempos de reconocimiento de las palabras escritas y diferentes los procesos sobre los que intervienen. Los efectos de algunas de esas variables, como la frecuencia, la edad de adquisición o la imaginabilidad, son compartidos por el reconocimiento oral de palabras y la lectura. Cuantas más veces vemos escrita una palabra, menos tiempo tardamos en reconocerla. Lo mismo sucede con la edad de adquisición, que es otra variable sumamente importante en el reconocimiento de las palabras escritas, con independencia de la metodología que se utilice. Asimismo, la vecindad ortográfica, o número de palabras que comparten con ella todas sus letras excepto una y en las mismas posiciones, también influye sobre los tiempos de reacción. Sin embargo, la variable punto de unicidad apenas tiene importancia en la lectura, puesto que la palabra aparece completa ante nuestros ojos y las letras son identificadas todas a la vez en paralelo (al menos con las palabras frecuentes). El papel de la sílaba en castellano ha sido muy estudiado, y se ha comprobado que las palabras formadas por sílabas muy frecuentes dan lugar a tiempos más lentos que las palabras formadas por sílabas poco frecuentes. Por otra parte, no todas las sílabas son igualmente importantes; hay evidencia de que la primera sílaba tiene un estatus especial en el proceso de activación de una unidad léxica. Por último, hay una variable sumamente influyente sobre la velocidad lectora, pero que sólo afecta a los idiomas de ortografía opaca, como el inglés, que es la regularidad entre las formas escritas y su pronunciación.
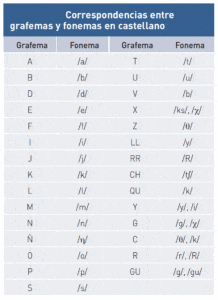
Los diferentes idiomas varían notablemente en la regularidad de sus sistemas ortográficos. En castellano, al ser un idioma con un sistema ortográfico muy transparente, no existe ese problema, ya que todas las palabras son regulares y uno puede leer sin dificultad cualquier palabra aunque nunca la haya visto. Sólo existen algunas palabras extranjeras, de uso cada vez más común, que se conservan en su forma ortográfica y pronunciación, como ‘Bollywood’. La mayoría de las palabras extranjeras las regularizamos: esta regularidad del castellano es una de las
principales causas de que los niños españoles aprendan a leer con relativa rapidez.
Hay que ser muy cuidadoso cuando se realiza una selección de palabras para un experimento o incluso para un estudio con pacientes que tienen trastornos del lenguaje. No se puede concluir que una variable influye sobre los resultados si no se han tenido en cuenta las otras variables, más aun si se considera que muchas variables están muy asociadas entre sí y presentan altas correlaciones.
¿Se mantienen esos efectos cuando las palabras aparecen dentro de un texto? Ciertamente, el contexto facilita el reconocimiento de las palabras, pues cuando una palabra forma parte de un texto o va precedida de otra relacionada (experimentos de priming) los tiempos de respuestas son más rápidos. Además, el contexto modula el papel de las variables, de manera que una variable como la imaginabilidad, influyente cuando se presentan palabras aisladas, puede no tener efectos significativos cuando se presentan textos. Lo que sí se sabe desde hace tiempo es que el contexto ayuda a reconocer las palabras, pero no parece influir en el acceso al significado.
Modelos de reconocimiento de palabras escritas
Actualmente los dos modelos más conocidos son el modelo dual y el de triángulo.
Modelo logogén
Propuesto inicialmente por Morton en 1969, intentaba explicar los datos para el reconocimiento de palabras tanto escritas como habladas. Se trata de un modelo de activación, dado que cada palabra está representada por un mecanismo (logogén) que se activa cuando se corresponde con el estímulo que se está procesando. Así, cuando una persona lee la palabra «corrupción», se activará el logogén correspondiente a esa palabra. Cada vez que se activa un logogén su umbral de activación disminuye, de manera que cuantas más veces se lea una palabra más fácil resulta reconocerla.
Modelo de búsqueda
Propuesto por Forster en 1976, utiliza la metáfora de la biblioteca. De la misma manera que en las bibliotecas hay archivos en los que se encuentran las fichas de los libros por distintos órdenes (alfabético, temático, etc.) y hay estanterías en las que se encuentran los libros, en este modelo hay también unos archivos periféricos donde se encuentran las representaciones de las palabras. Distingue tres tipos de archivos: fonológico para el lenguaje oral, ortográfico para el escrito y sintáctico-semántico. Además, está el archivo general, donde se almacena toda la información referente a la palabra, incluido el significado.
El modelo dual
| Coltheart (1978); Coltheart et al. (2001). El modelo dual fue propuesto por Coltheart a partir del modelo logogén, añadiendo nuevos componentes para explicar los datos que iban surgiendo tanto desde la psicología experimental con individuos sanos, como desde la neuropsicología con pacientes que habían sufrido lesiones cerebrales. |
| Cuetos y Suárez-Coalla (2009). En un estudio realizado con niños durante los primeros años de aprendizaje de la lectura encontraron que la longitud influía notablemente en los primeros cursos, pero su influencia descendía paulatinamente a medida que se ascendía de nivel. Por el contrario, la frecuencia no influía en los primeros niveles pero sí en los superiores. |
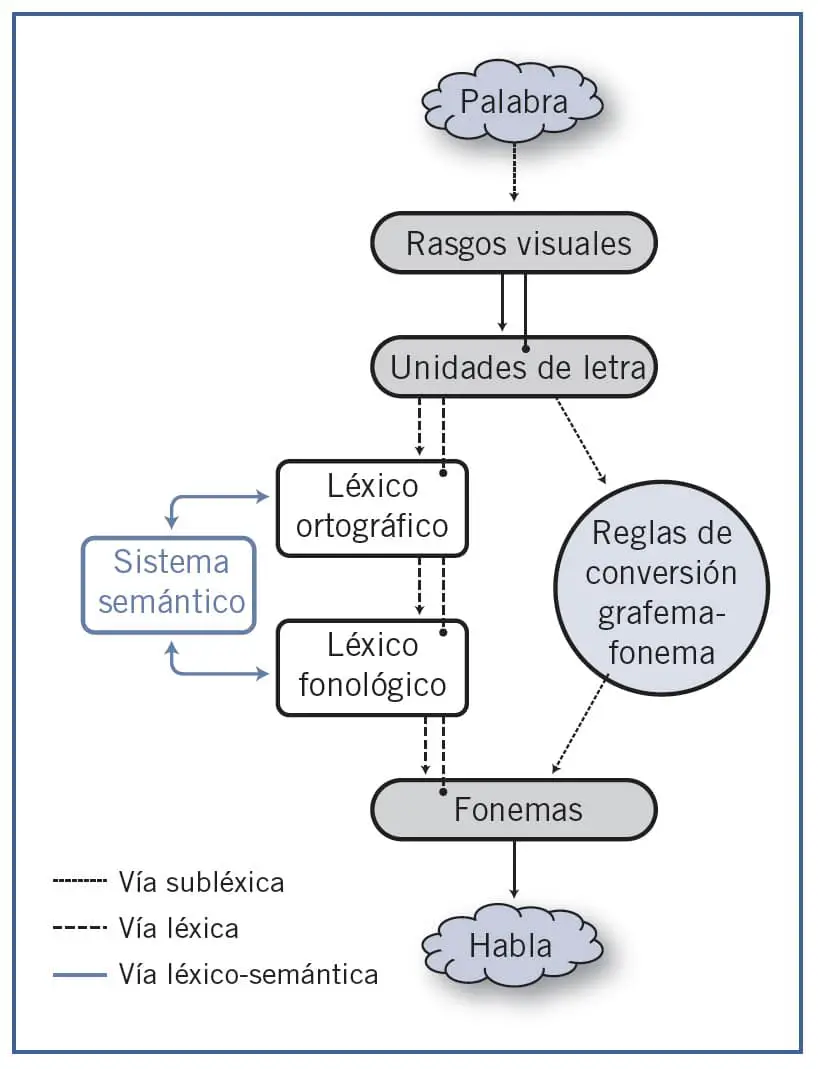
El modelo dual propone dos vías o procedimientos para pasar de la palabra escrita al significado (en el caso de la lectura comprensiva) o a la pronunciación (en el caso de la lectura en voz alta): la vía subléxica, que permite leer las palabras mediante la aplicación de las reglas grafema-fonema, transformando cada letra o grafema en su correspondiente fonema, y la vía léxica, que permite leer directamente las palabras al activar las representaciones que de ellas tenemos en nuestro léxico visual. Esta vía léxica tiene, en realidad, dos variantes: la vía léxica pura, que conecta directamente el léxico ortográfico con el fonológico, lo que permite reconocer las palabras y leerlas en voz alta sin entrar en su significado, y la vía lexicosemántica, que pasa por el sistema semántico. Esta última vía es indispensable para comprender las palabras.
La vía léxica es muy útil porque permite leer de una manera más fluida al reconocer y pronunciar directamente las palabras. Pero sólo se puede utilizar con las palabras familiares que ya se han leído en ocasiones previas para poder tener representación de ellas en el léxico. La vía subléxica, en cambio, se puede utilizar con cualquier palabra, sea familiar o no, e incluso con palabras desconocidas y seudopalabras, porque las reglas grafema-fonema son aplicables a cualquier estímulo, siempre que la pronunciación sea regular. Tanto cuando se utiliza la vía léxica como la subléxica, el primer paso que se ha de realizar es siempre el de identificación de las letras. A partir de ahí ya se puede tomar una de las dos vías (o las dos). Si nunca hemos visto la palabra que tenemos delante, por ejemplo, «golimbro» (aficionado a comer golosinas), entonces no podremos tener una representación de ella en nuestro léxico y la única forma de leerla será aplicando las reglas de conversión grafema-fonema. Sabemos cómo se pronuncian la «g», la «O», la «l», la «i», etc., así que podremos pronunciar todas las letras y leer en voz alta la palabra. Si, por el contrario, la palabra que tenemos delante es conocida pero de pronunciación irregular, esto es, no se ajusta a las reglas grafema-fonema (p. ej., Bollywood) entonces sólo podremos leerla a través de la vía léxica, reconociendo su forma en el léxico visual y recuperando su pronunciación en el léxico fonológico. Cuando se trata de una palabra familiar y regular, se ponen en marcha las dos vías, lo que facilita una lectura rápida y precisa. En cualquier caso, sea cual fuere la palabra, las dos vías se ponen en funcionamiento. Ésta es la razón de que cometamos tan pocos errores en la lectura, porque si falla una de las vías está la otra para sustituirla. Contrariamente a la vía subléxica, que tiene que ser enseñada de manera sistemática, la vía léxica no requiere un aprendizaje sistemático, sino que son los propios niños quienes al leer una y otra vez las palabras terminan formando representaciones de esas palabras. Es lo que Share denomina autoaprendizaje.
El modelo de triángulo
| McClelland y Rumelhart (1981). Modelo procesamiento distribuido en paralelo (POP). |
| Seidenberg y McClelland (1989). El modelo de triángulo es un modelo conexionista, propuesto por Seidenberg y McClelland a partir del modelo procesamiento distribuido en paralelo (POP), formulado por McClelland y Rumelhart en 1981 . |
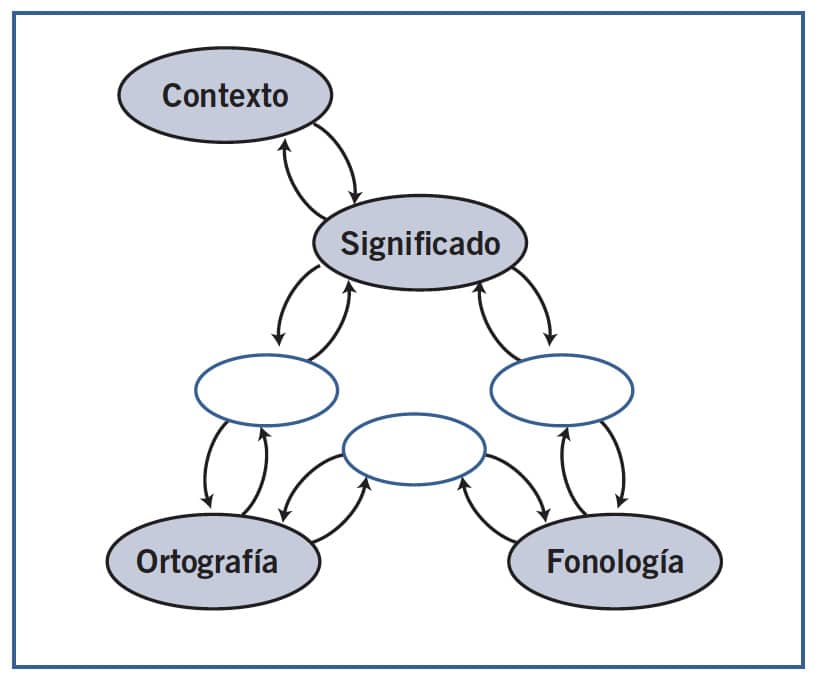
de la fonología.
Este modelo propone tres componentes, ortográfico, fonológico y semántico, unidos entre sí mediante conexiones y en el que la velocidad de lectura depende de la fortaleza de esas conexiones. Este modelo no distingue entre vía léxica y vía subléxica, puesto que todos los estímulos, sean palabras familiares, palabras desconocidas o incluso seudopalabras, se leen por el mismo procedimiento. Contrariamente a los modelos simbólicos como el dual, los modelos conexionistas no conciben el sistema de lectura formado por módulos, sino por redes compuestas por un gran número de unidades o nodos conectados entre sí y que funcionan de manera similar a las redes neuronales.
Ventajas sobre el Modelo Dual:
- Los distintos componentes del sistema trabajan en paralelo, por lo que no es necesario que un componente termine de funcionar para que empiece a funcionar el siguiente (algo que también ocurre en el funcionamiento cerebral).
- Se trata de un sistema que mejora con la práctica, por lo que sirve para explicar el aprendizaje de la lectura. Este modelo no incluye reglas de conversión grafema-fonema, sino que la relación entre las letras y los sonidos aparece en el curso del entrenamiento del sistema.
Otros modelos
| Ans, Carbonell y Valdois (1998). Propusieron un modelo de lectura de tipo conexionista que sirve para cualquier palabra, corta o larga, familiar o desconocida. De acuerdo con este modelo, el sistema lector cuenta con dos procedimientos que trabajan de manera sucesiva: un procedimiento global, que usa el conocimiento completo de la palabra y permite leer las palabras familiares, y un procedimiento analítico, que se basa en la activación de los segmentos silábicos de las palabras y funciona cuando no se puede reconocer globalmente la palabra. |
| Perry, Ziegler y Zorzi (2007). En un intento de aprovechar las ventajas del modelo Dual y el modelo de triangulo elaboraron un nuevo modelo que supone una síntesis de los dos. Parte de los supuestos conexionistas, pero incorpora las vías léxica y subléxica. La lectura es el resultado de ambas vías, que se unen en el almacén de salida fonológica. Gracias a su arquitectura conexionista este modelo es capaz de aprender, lo que lo coloca en ventaja respecto al modelo dual, y gracias a su vía subléxica consigue mejores resultados con las seudopalabras y replica la interacción entre frecuencia y longitud, lo que lo sitúa en ventaja respecto al modelo de triángulo. |
BASES NEUROLÓGICAS DE LA LECTURA
| Cohen et al. (2000).También es muy importante la zona occipito temporal, responsable del reconocimiento ortográfico de las palabras. A esta área se la conoce como área de la forma visual de las palabras. |
| Paulesu et al. (2000). Compararon mediante tomografía por emisión de positrones la activación cerebral de estudiantes ingleses e italianos mientras leían palabras y seudopalabras, y comprobaron que los italianos presentaban mayor activación en la circunvolución temporal superior (componente del circuito dorsal), mientras que los ingleses tenían mayor activación en el área de la forma de la palabra (componente del circuito ventral). |
En el poco tiempo que tardamos en leer en voz alta una palabra (unos 500 ms por término medio) y comprenderla (otros 250 ms), realizamos un buen número de operaciones cognitivas: Análisis visual, identificación de las letras, procesamiento fonológico, procesamiento semántico, etc. Se calcula que aproximadamente los primeros 100 ms se destinan al procesamiento visual de la palabra (análisis de los rasgos visuales e identificación de las letras) y los 150 ms siguientes al procesamiento fonológico y semántico. Los 250 ms restantes, hasta completar los 500 ms, se emplean en activar y ejecutar los programas motores para pronunciar las palabras.
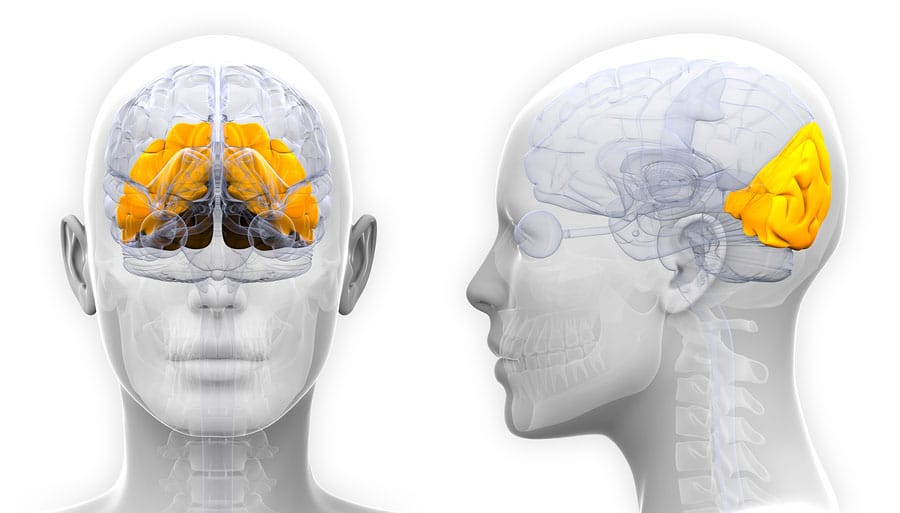
Las primeras zonas cerebrales que se ponen en funcionamiento cuando leemos tienen que ser las áreas visuales, situadas en los lóbulos occipitales. En esas áreas se realizan las primeras operaciones de análisis de los rasgos de las letras para conseguir identificarlas. Las últimas zonas del cerebro que entran en funcionamiento son las áreas motoras en los lóbulos frontales, desde donde se envían las órdenes a los músculos del aparato fonador (laringe, lengua, labios, etc.) para la articulación de los fonemas.
Entre esas dos áreas hay muchas otras, fundamentalmente en el hemisferio izquierdo, que también se ponen en funcionamiento para llevar a cabo el procesamiento fonológico, ortográfico y semántico. Una de las áreas más importantes y donde mayor activación se produce cuando leemos es la zona parieto temporal, que incluye el área de Wernicke y las circunvoluciones angular y supramarginal. En esta área se integra la información visual con la fonológica y donde se realiza la conversión de los grafemas en fonemas para que las palabras puedan ser reconocidas como si se tratase de palabras habladas. También es muy importante la zona occipito temporal, responsable del reconocimiento ortográfico de las palabras.
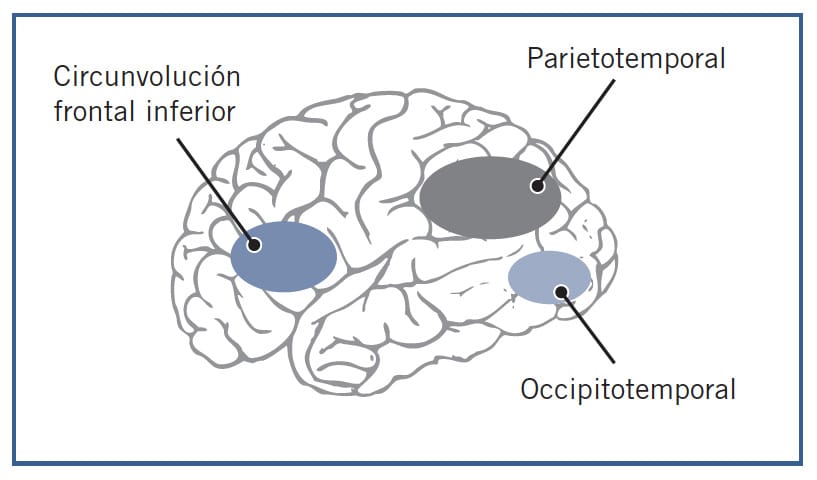
Otro área importante en el procesamiento lector es la que corresponde a las zonas media e inferior del temporal izquierdo. En esta zona se lleva a cabo el procesamiento semántico de las palabras. Las lesiones en estas zonas producen pérdida de información semántica. Finalmente, la zona que participa en la lectura se encuentra en el lóbulo frontal izquierdo, concretamente en el área de Broca. Aquí se realiza la recodificación fonológica necesaria para la pronunciación. Desde aquí se envían las órdenes al área motora para ejecutar los movimientos encargados de producir el habla.
A medida que los niños van leyendo las palabras una y otra vez terminan formando representaciones ortográficas de esas palabras, por lo que ya no necesitan convertir cada letra en su sonido, sino que pueden leerla de manera global, identificando todas las letras en paralelo, lo que produce una lectura más fluida, aunque esta representación ortográfica no serviría de mucho si no se asociara con su pronunciación y significado. En consecuencia, cuando el niño empieza a leer globalmente las palabras, comienza a desarrollar una nueva vía que conecta el área de la forma de la palabra con su significado en el temporal medio e inferior. Esta conexión sería suficiente para realizar la lectura comprensiva.
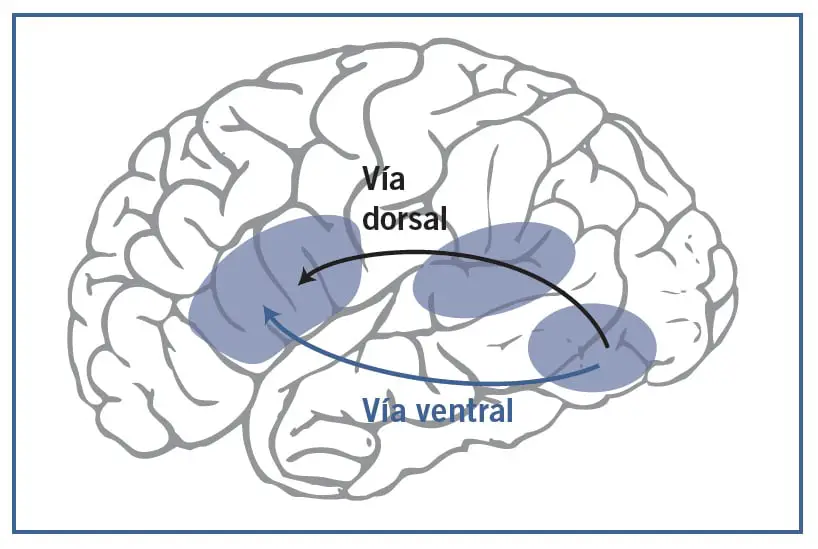
Con la lectura léxica se desarrolla esta segunda vía, que se denomina circuito ventral. En los lectores expertos, los dos circuitos participan en el proceso de lectura, si bien el papel de cada uno depende de varios factores. El circuito dorsal tiene gran actividad en los comienzos del aprendizaje de la lectura y, de hecho, en los niños que están aprendiendo a leer es el único que se activa. Se encarga fundamentalmente de procesar las palabras desconocidas y seudopalabras. En realidad, equivale a la vía subléxica en el modelo dual o a la conexión ortografía-fonología en el modelo de triángulo. En cambio, el circuito ventral se activa más cuanto más experto sea el lector y funciona más con las palabras familiares, especialmente las irregulares. Equivale a la vía lexicosemántica en el modelo dual o a la conexión ortografía-semántica en el modelo de triángulo.
ESQUEMA
AUTOEVALUACIÓN
REFERENCIAS
- Cuetos Vega, González Álvarez, Vega, and Vega, Manuel De. Psicología Del Lenguaje. 2ª Edición. ed. Madrid: Editorial Médica Panamericana, 2020.
- PDF Profesor tutor Pedro R. Montoro
