

INTRODUCCIÓN
Cuando hacemos una predicción o pronóstico (“La pandemia del Covid-19 pondrá en valor la necesidad de un sistema de sanidad público, universal y de calidad”), tomamos una decisión (“Yo me quedo en casa”) o buscamos la causa de un hecho determinado (“A votado a VOX porque es una ignorante”) estamos evaluando la probabilidad de que determinados acontecimientos vayan a ocurrir o hayan ocurrido. Nuestras predicciones sobre acontecimientos futuros se basan en información incompleta, parcialmente imprevisible y ambigua, en los que la certeza de nuestros juicios se sitúa en un margen determinado de probabilidad. Es un margen de incertidumbre. El razonamiento probabilístico es importante en el ámbito profesional cuando no pueden contemplarse en su totalidad todas las variables posibles que influyen o dan lugar a una determinada consecuencia. Así, el diagnóstico clínico en medicina y psicología, la potencial eficacia de metodologías innovadoras en educación, las sentencias judiciales, las previsiones basadas en estudios de mercado, o los pronósticos electorales constituyen ejemplos de juicios predictivos en los que las conclusiones no son “inequívocamente” ciertas sino “probablemente” ciertas.
El razonamiento probabilístico constituye una modalidad de pensamiento que se enfrenta a problemas abiertos y, por tanto, no muy bien delimitados, en un mundo complejo y cambiante en el que la información es incompleta y se modifica temporalmente. Para adaptarnos de manera eficaz a la incertidumbre y variabilidad ambiental esta modalidad de razonamiento genera formas de percibir, computar y representar las variables externas para emitir juicios de probabilidad que permitan estimar esa variabilidad y actuar sobre el entorno. Las leyes de la probabilidad en tareas de razonamiento probabilístico juegan un papel similar a las leyes de la lógica en el razonamiento deductivo y constituyen un modelo normativo o prescriptivo sobre cómo deben realizarse las inferencias probabilísticas.
EL TEOREMA DE BAYES
Cuando asignamos un valor de probabilidad a un suceso podemos conocer o no el espacio de probabilidades. Si se conoce como en el lanzamiento de un dado o de moneda, asumiendo la equiprobabilidad de las diferentes posibilidades, la probabilidad de un suceso aleatorio sería el cociente entre el número de resultados favorables y el número total de resultados posibles. Si se repite el lanzamiento de un dado, la probabilidad de sacar un dos será equivalente a su frecuencia de 1/6. En la vida diaria, no conocemos el espacio completo de probabilidades en relación a un suceso determinado, por lo que estimamos subjetivamente en relación al espacio muestral, añadiendo que las diferentes alternativas no sean necesariamente equiprobables.
La Teoría de la probabilidad asume un conjunto de axiomas. El espacio de probabilidades que ofrece el ejemplo siguiente nos permitirá introducir y ejemplificar cada uno de ellos. Imaginemos que a la consulta del gabinete psicológico de Ana acudieron el pasado año 100 pacientes. De los 100 pacientes, 30 sufrían trastorno depresivo, 20 pacientes fueron diagnosticados de fobias específicas, y los 50 pacientes restantes de problemas de ansiedad.
Ilustremos ahora los axiomas que asume la teoría de la probabilidad supuesto este espacio de probabilidades:
- La probabilidad de un suceso (S) varía entre 0 (imposibilidad) y 1 (certeza). La probabilidad de sufrir un trastorno de ansiedad es de 50/100 = 0,50. La probabilidad de sufrir un trastorno depresivo es de 30/100 = 0,30. La probabilidad de sufrir fobia específica es de 20/100 = 0,20.
- La suma de las probabilidades de todos los posibles sucesos en un espacio muestral dado es 1. La probabilidad de “NO OCURRENCIA” de un suceso (S) es igual a 1 menos la probabilidad de que sí ocurra. P (noS) = 1- P(S). • La suma de las probabilidades de todos los posibles sucesos = (30/100) + (20/100) + (50/100) = 1
- Si dos sucesos (S1) y (S2) son mutuamente excluyentes, la probabilidad de S1 ó S2 será igual a la suma de sus probabilidades. P (S1 ó S2) = P(S1) + P(S2). • La probabilidad de sufrir un trastorno depresivo o de sufrir una fobia específica = (30/100) + (20/100) = 0,50
Terminada la primera fase del tratamiento, el porcentaje de curación en el grupo de pacientes con trastorno depresivo fue del 50%, en el grupo con problemas de fobias del 70 %, y del 40 % en el grupo de pacientes con problemas de ansiedad. Conociendo estos datos podremos ejemplificar el cuarto axioma.
- a) Si dos sucesos (S1 y S2) son dependientes, la probabilidad de la conjunción de estos sucesos será igual al producto de la probabilidad de S1 por la probabilidad de S2 asumiendo S1: P (S1 y S2) = P (S1) x P (S2 dado S1) = P (S1) x P (S2|S1). El segundo factor de este producto se denomina probabilidad condicional de S2 dado S1. • La probabilidad de que un paciente haya sido diagnosticado de ansiedad y se haya curado= P (Ansiedad) x P (Curado|Ansiedad) = 0.50 x 0.40 = 0.20.
b) Si dos sucesos (S1 y S2) son independientes, la probabilidad de la conjunción de estos sucesos será igual al producto de la probabilidad de S1 por la probabilidad de S2. P (S1 y S2) = P (S1) x P (S2).
Imaginemos ahora que del conjunto de pacientes que asistieron a terapia el año pasado extraemos uno al azar y encontramos que está curado. ¿Cuál es la probabilidad de que dicho paciente hubiera sido diagnosticado previamente de trastorno depresivo?
Thomas Bayes (siglo XVIII) añadió a esos axiomas una fórmula conocida como el Teorema de Bayes, el cual permite calcular la probabilidad condicional inversa, también denominada probabilidad posterior (o probabilidad a posteriori). El cálculo no es directo ya que conocemos el dato (el paciente está curado) pero tenemos tres posibles opciones de diagnóstico previo o hipótesis de partida: depresión, fobia o ansiedad. El teorema constituye la ley fundamental en la que se basa este tipo de inferencia probabilística, tanto cuando la información procede de datos muestrales como cuando es de estimaciones subjetivas de probabilidad.
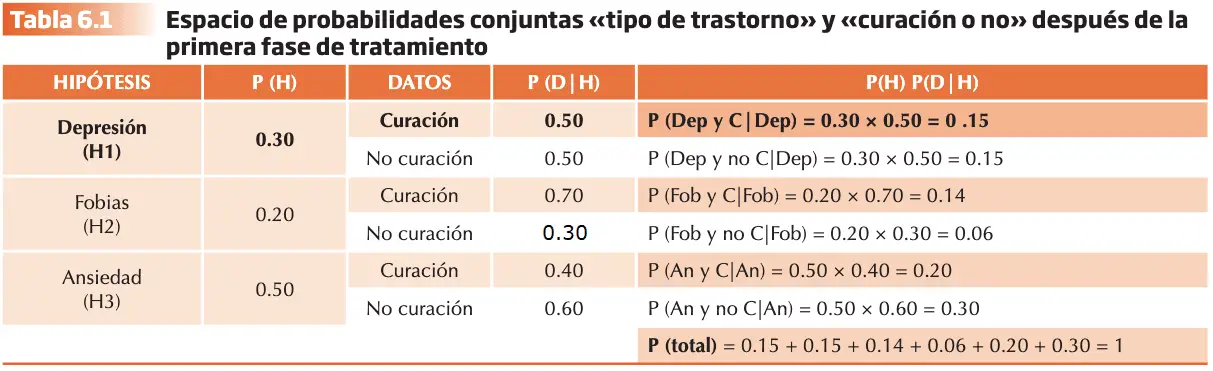
- La probabilidad a priori de la Hipótesis: P(H). La hipótesis relevante para el problema que tenemos. P (depresión).
- La diagnosticidad del Dato para la hipótesis: P (D|H). En el problema planteado P (curación |Depresión). Este valor recibe el nombre de diagnosticidad del dato (curación) y se puede dar en presencia de otras dos posibles hipótesis alternativas: P (D|H2) o P (D|H3).
- Con el producto de estos se obtiene la probabilidad conjunta de dos sucesos dependientes: Haber sido previamente diagnosticado de depresión y curarse dado el diagnóstico previo de depresión: P (H) x P (D|H). Siguiendo con el ejemplo sería: P(depresión) x P(curación|depresión).
- La probabilidad condicional inversa o posterior, que es el problema que debemos resolver a partir de la información de la que disponemos. Denominado así porque es la inversa de la condicional P (D|H) se conoce la probabilidad condicional de curarse habiendo sido diagnosticado de depresión: P(curarse|depresión). Sabiendo que un paciente extraído al azar está curado ¿cuál es la probabilidad de que hubiera sido previamente diagnosticado de depresión? P (H|D) o P(Depresión|curación).
Siguiendo el Teorema de Bayes, el cálculo sería el resultado de dividir la probabilidad de los casos favorables por la suma de las probabilidades de todos los casos posibles. El axioma 4 explica el numerador del Teorema (probabilidad de casos favorables) y el axioma 3 explica el denominador (suma de las probabilidades de los casos posibles.

Arieta Pinedo y González Labra (2011), postulan que la inferencia bayesiana permite introducir probabilidades subjetivas tanto al evaluar a priori como al evaluar las condiciones de un suceso. Pueden obtenerse de distintas fuentes, tales como la evidencia, teorías previas o simplemente de la opinión y creencias de la persona. La hipótesis alternativa es la ausencia de la hipótesis focal de tal forma que su probabilidad complementaria se calcula aplicando el axioma 2 de la Teoría de la probabilidad.

Volvemos al ejemplo de Ana, imaginemos otro experimento de razonamiento probabilístico cuyo objetivo es analizar en sujetos no expertos en teoría de la probabilidad cuál sería la solución al problema planteado sin necesidad de realizar cálculos matemáticos:
Problema A: Seleccionamos un paciente al azar y encontramos que está curado. ¿qué probabilidad será mayor?: a) fue diagnosticado de fobia específica. b) fue diagnosticado de ansiedad. Si el alumno ha elegido la alternativa a), su elección coincide con la de un porcentaje significativamente elevado de los participantes en el experimento, si bien su elección es incorrecta. Analicemos ahora el problema B y reflexionemos sobre cuál sería la elección de Elena.
Problema B: Ana plantea analizar qué variables explican que después de la primera fase del tratamiento sólo el 40% de los pacientes sanen de su ansiedad. Cita un día a todos los curados y en otro día a los que siguen en el proceso. Elena sufre de ansiedad y acude a consulta a pedir cita el día que ésta citó a los curados. En la sala coinciden con Elena y le transmiten a ésta el éxito y rapidez de curación tras la primera fase de tratamiento. A partir de la información Elena considera que la primera fase de tratamiento empleado por Ana para el tratamiento de la ansiedad: a) es altamente eficaz b) es parcialmente eficaz
Elena selecciona la alternativa a) y su respuesta es incorrecta. ¿A qué información relevante para resolver correctamente uno y otro problema no estaría atendiendo el participante en el problema A y E lena en el problema B? En el caso del problema A, contando con toda la información necesaria, el error se produce porque una mayoría de participantes se centran en el valor del porcentaje de curación (70 %), la diagnosticidad del dato con relación a la hipótesis, y desatienden a la probabilidad a priori de sufrir el trastorno (20 %). En el caso del problema B, Elena no cuenta con toda la información relevante para resolver el problema. En concreto, la diagnosticidad del dato (la aplicación de la primera fase del tratamiento) en presencia de la hipótesis alternativa (el paciente no se ha curado).
La evidencia empírica demuestra que el razonamiento probabilístico humano generalmente no es extensional (no contempla el conjunto de probabilidades de forma exhaustiva). En el problema A, se desatiende al porcentaje sobre el total de 100 casos que fueron diagnosticados de los diferentes trastornos. En el apartado siguiente abordaremos el estudio de estrategias y procedimientos psicológicos que facilitan y hacen más rápido y menos costoso el proceso de asignación de probabilidades, que si se realizasen los complejos cálculos matemáticos basados en modelos normativos como el Teorema de Bayes. En muchas ocasiones, las estrategias conducen a resultados correctos y son efectivas y económicas en tiempo y esfuerzo cognitivo, pero pueden resultar a la vez imprecisas.
ENFOQUE DE LOS HEURÍSTICOS
Los heurísticos constituyen reglas y estrategias intuitivas, que se aplican deliberadamente o no para estimar o predecir. Con frecuencia, al margen de consideraciones básicas de la teoría de la probabilidad, puede dar lugar a distintos errores sistemáticos (sesgos o falacias) característicos de cada uno de ellos. El estudio de los sesgos y errores sistemáticos se investiga en el razonamiento probabilístico, también desde los principios de la percepción normal y desde la memoria estudiando el olvido.
Teversky y Kahneman (1974; 1982a) iniciaron y desarrollaron un programa de investigación que sustenta los tipos básicos de heurísticos: representatividad, accesibilidad, anclaje y ajuste. Más recientemente se contempla el estudio desde un modelo más integrador.
Heurístico de representatividad.
Los juicios probabilísticos responden a una de las siguientes preguntas:
- ¿Cuál es la probabilidad de que el objeto A pertenezca a la categoría B?
- ¿Cuál es la probabilidad de que el proceso B sea la causa del acontecimiento A?,
- ¿Cuál es la probabilidad de que el dato A se genere a partir del modelo B?
La investigación ha demostrado que la información de los prototipos y esquemas contribuyen significativamente a la forma en que almacenamos y procesamos la información. Natural y económico cognitivamente el juzgar la probabilidad de un evento evaluando el grado en el cual es representativo de la categoría de referencia. Esta estrategia para abordar estos juicios probables produce sesgos significativos pues la semejanza no se ve afectada por factores que deberían afectar a los juicios de probabilidad. Dicha insensibilidad a estos factores es estudiada por Tversky y Kahneman (1974).
Insensibilidad a las probabilidades a priori
Uno de estos factores que no afectan a la representatividad, aunque debiera tener efecto sobre el juicio probabilístico es la probabilidad a priori o la frecuencia base del resultado (Tversky y Kahneman, 1982b). Para contrastar dicha hipótesis Kahneman y Tversky realizaron el siguiente experimento: Los participantes analizaron descripciones de personalidades de una muestra de 100 individuos (ingenieros y abogados).
- A una condición experimental se les indica que 70% son ingenieros y 30 % abogados.
- En la otra condición, es 30% de ingenieros y 70 % de abogados.
Un ejemplo de descripción es la siguiente: Jack tiene 45 años, casado y cuatro hijos. Conservador, prudente y ambicioso. No manifiesta intereses políticos y sociales y emplea su tiempo libre en sus aficiones (carpintería, navegar, resolver problemas matemáticos) La probabilidad de que sea uno de los 30 ingenieros de la muestra de 100 es _%.
La probabilidad de pertenecer al grupo de ingenieros debería ser mayor en la primera condición, y la probabilidad de pertenecer al grupo de abogados debería ser mayor en la segunda condición. Los participantes violaron drásticamente la predicción del Teorema de Bayes, pues en ambas condiciones se produjeron los mismos juicios. Evaluaron la probabilidad de que una determinada descripción perteneciera a un ingeniero frente a un abogado en función del grado en que dicha descripción era representativa de uno u otro estereotipo, atendiendo bien poco a las probabilidades a priori de las categorías.
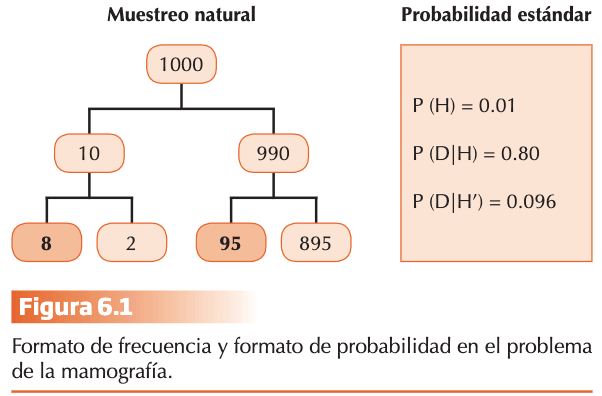
La dificultad para aplicar el algoritmo necesario para calcular correctamente la probabilidad de un acontecimiento contemplando las probabilidades a priori ha sido también demostrada con participantes expertos. Veamos el problema ya clásico que Eddy (1982) planteó a un grupo de médicos: La probabilidad de cáncer de mama en mujeres de 40 años es del 1%. Si una padece cáncer la probabilidad de que la mamografía resulte positiva es del 80%. La probabilidad de que no padezca cáncer de mama tenga un resultado positivo es una mamografía es del 9,6%. Una mujer de 40 años obtiene resultado positivo en la mamografía en un control. ¿cuál es la probabilidad de que la mujer padezca de hecho cáncer de mama? _%.
Puedes aplicar el Teorema de Bayes y comprobar que el resultado es 7.8 %. De acuerdo con los resultados de Eddy (1982), el 95 % de los médicos estimaron que la probabilidad (cáncer/resultado positivo) fluctuaría entre el 70 % y el 80 %. Cuando concluida la investigación se informó a los médicos de su error y se les preguntó sobre las causas posibles de éste, la gran mayoría afirmó que había asumido que la probabilidad de cáncer con mamografía positiva [P(cáncer/resultado positivo)) era aproximadamente igual a la probabilidad de una mamografía positiva en una paciente con cáncer [P(resultado positivo/cáncer)], pasando por alto, así, la probabilidad a priori de padecer la enfermedad en la muestra de mujeres de 40 años.
Gigerenzer y Hoffrage (1995) postulan que los trabajos que apoyan la dificultad de los humanos para aplicar las normas de la inferencia bayesiana es el resultado de un planteamiento metodológico inadecuado: desajuste entre la forma en la que se presenta la información a los participantes y el formato de la representación cognitiva natural de dicha información. Gigerenzer y Hoffrage se basan en la teoría de la evolución, donde la mente y su entorno han evolucionado en paralelo. Éstos sostienen que las demandas computacionales de los algoritmos bayesianos son más simples cuando la información se codifica en un formato de frecuencias más que en el formato estándar de probabilidad.
La probabilidad de cáncer es de 10/1000 = 1% P (H) = 0,01; De cada 10 mujeres que padecen cáncer, 8 dan un resultado positivo en la mamografía. Una mujer sin cáncer (990) dé resultado positivo en la mamografía es de 95/990. Una mujer de 40 años obtiene un resultado positivo en la mamografía en un control rutinario ¿Cuál es la probabilidad de que la mujer padezca de hecho cáncer de mama? __%.
Si presentamos los datos con el formato de muestreo natural, la fórmula del teorema de Bayes se simplifica mucho:
El algoritmo bayesiano para calcular la probabilidad posterior P (H|D) sería el resultado de dividir el número de casos con síntoma y enfermedad (dato e hipótesis) por el número total de casos con síntoma (casos con síntoma y enfermedad + casos con síntoma y sin enfermedad H´). Todo sería más simple cuando la información se codifica en el formato natural de frecuencias más que en el formato estándar de probabilidad, entre otras razones, porque las probabilidades a priori no necesitan ser atendidas, lo cual, afirman, es perfectamente racional en el muestreo natural. Diferentes estudios comparativos entre las dos modalidades (formato de frecuencias vs. Formato probabilístico) indicaron que el promedio de algoritmos bayesianos correctos incrementó del 16% (formato probabilístico) al 46% (formato de frecuencias).
Insensibilidad a la capacidad predictiva del dato
Supongamos que una estudiante recién llegada a un instituto es descrita por el orientador como inteligente, con buena base y trabajadora. Se plantean 2 preguntas:
- Evaluación: ¿Qué impresión te produce esta descripción en relación con la habilidad académica del estudiante?
- Predicción: ¿cuál estimas sería la calificación media que el estudiante obtendrá cuando termine el curso?
Existe la gran diferencia entre ambas, en que en la primera se evalúa el dato, y en la segunda se predice el resultado. Se da un grado superior de incertidumbre en relación con la segunda pregunta.
La hipótesis de representatividad sostiene que predicción y evaluación deberían coincidir. Teversky y Kahneman (1973) lo pusieron a prueba y consistía en describir en cinco adjetivos referentes a la calidad intelectual del estudiante y rasgos de su personalidad:
- El grupo de evaluación valoraba la calidad de la descripción en relación a la población. Este ordenaba la capacidad académica de todos los estudiantes. (0 a 100)
- El grupo de predicción predecía el rendimiento futuro. Ordenaba calificaciones medias que obtendrían a final de curso. (0 a 100)
Los resultados se transformaron a percentiles y se dispuso en gráfica que representaba la capacidad predictiva de la evaluación sobre la media de la predicción de su calificación final. Los juicios de ambos grupos fueron similares. En la teoría estadística de la predicción, la equivalencia observada estaría justificada sólo si la eficacia predictiva fuese perfecta (condición alejada de cumplirse en el ejemplo). La descripción no es objetiva, pues las circunstancias personales del estudiante no serán siempre favorables durante el curso, perjudicando así su rendimiento. Los sujetos parecen ignorar la probabilidad del dato dada la hipótesis alternativa [P (D|H´)].
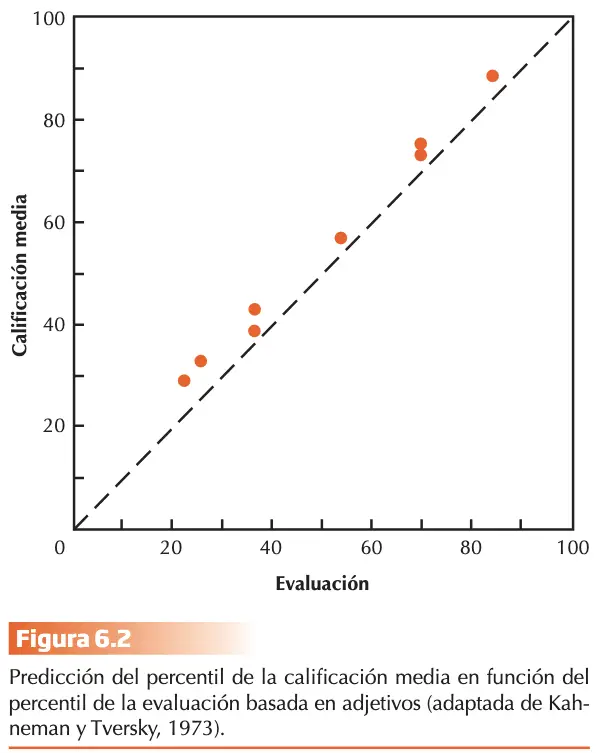
La predicción basada en la “impresión” de la descripción sin considerar otros factores que afectan, da lugar a sesgos sistemáticos en el juicio probabilístico que responden al concepto de “ilusión de validez”.
Concepciones estadísticas inexactas
La idea errónea de la regresión constituye otro ejemplo de sesgo en el juicio predictivo basado en el heurístico de representatividad. Se usa la regresión para predecir una medida basada en el cono- cimiento de otra. La regresión estadística es la tendencia de una medición extrema a situarse más próxima a la media cuando se realiza una segunda medición.
Supongamos que un grupo grande de niños ha realizado dos versiones equivalentes de una prueba de aptitud y que seleccionamos cuatro grupos de niños: los 10 con mejores resultados y los 10 con peores resultados en cada una de las dos versiones. Observaremos que los 10 mejores en cada versión mostraron un rendimiento promedio inferior en la versión alternativa, y que los 10 peores en cada versión rindieron en promedio mejor en la versión alternativa. En la vida cotidiana encontramos muchos ejemplos de este fenómeno cuando comparamos la altura o la inteligencia de padres e hijos o el rendimiento de las personas en exámenes consecutivos. Sin embargo, las personas no desarrollan intuiciones correctas en relación a este fenómeno en la medida en que es incompatible con la creencia de que el resultado predicho debería ser representativo al máximo de la evidencia disponible y, por tanto, tan extremo como ésta.
Otro resultado en relación con el heurístico de representatividad se observa cuando se evalúa la probabilidad de obtener un resultado determinado en una muestra extraída de una población específica. El siguiente experimento ilustra muy bien este sesgo denominado insensibilidad al tamaño de la muestra. Los participantes recibieron la siguiente información:
Existen dos hospitales en el lugar, uno grande y otro pequeño:
- En el grande nacen una media de 45 bebés al día (días habrá más y días habrá menos).
- En el pequeño nacen una media de 15 bebés.
- Sabemos que aproximadamente el 50% de los bebés son niños (varones). Sin embargo, el porcentaje exacto varía cada día.
- Durante el período de un año, cada hospital registró el número de días en los cuales el 60% de los nacimientos fueron varones. ¿qué hospital registró un nº superior de esos días? El hospital grande (21) El hospital pequeño (21) Aproximadamente el mismo (esto es, menos de un 5 por 100 de diferencia entre ambos) (53). Los valores entre paréntesis corresponden al número de participantes que eligieron cada respuesta. La mayor parte de los participantes juzgó que la probabilidad era la misma en ambos hospitales, presumiblemente porque se describe con el mismo estadístico, que se considera igualmente representativo de la población general. En contraste, la teoría del muestreo sostiene que el número debería ser superior en el hospital pequeño porque en una muestra de gran tamaño es más difícil superar el 50 %. La insensibilidad al tamaño de la muestra explica también nuestras expectativas en los juegos de azar, en la medida en que esperamos que las muestras pequeñas de procesos aleatorios representen el proceso con un elevado número de ensayos. Esta expectativa basada en la intuición de representatividad “local” explica el fenómeno conocido como la falacia del jugador. Después de observar una secuencia de números rojos en la ruleta, la mayor parte de la gente esperaría de forma errónea que ha llegado el turno del número negro, presumiblemente porque la ocurrencia de “negro” resultaría en una secuencia más representativa que la ocurrencia de un “rojo” adicional.
Teversky y Kahneman (1971) estudiaron las intuiciones estadísticas de psicólogos experimentados y demostraron que la concepción errónea del azar no se limita a personas ingenuas. La creencia en la “ley de los números pequeños “revela que la expectativa de una hipótesis válida en relación con una población puede basarse en la significación estadística de un resultado en una muestra, prestando poca consideración al tamaño de ésta. Como consecuencia, los investigadores corren el riesgo de atribuir excesiva fiabilidad a resultados obtenidos con muestras pequeñas y sobreestimar la replicabilidad de sus resultados.
La falacia de la conjunción
La representatividad no siempre está determinada por la frecuencia ni por la inclusión de clases de los datos que componen el espacio muestral. En el modelo normativo de la teoría de la probabilidad, la ley más simple y fundamental desde un punto de vista cualitativo es el principio de la extensión: si la extensión de A incluye la extensión de B (es decir A ? B), entonces P(A) ? P(B). Puesto que el conjunto de posibilidades asociadas con la conjunción A y B está incluida en el conjunto de posibilidades asociadas con A, puede aplicarse el mismo principio para la conjunción: P(A) ? P (A y B). Una conjunción no puede ser nunca más probable que cada uno de sus constituyentes. Este principio se aplica tanto si A y B son o no independientes y es válido para cualquier valor de probabilidad del mismo espacio muestral.
El problema de Linda (muy citado a este respecto) describe el caso de mujer de 31 años, soltera, sincera y muy brillante. Licenciada en Filosofía. Cuando era estudiante estaba profundamente comprometida en temas de discriminación y justicia social, participando también en manifestaciones antinucleares. Se presentan las opciones:
- a) Linda es una maestra en escuela elemental.
- b) trabaja en una librería y asiste a clases de yoga.
- c) es feminista.
- d) es asistente social en psiquiatría
- e) es miembro de la Liga de Mujeres Votantes.
- f) es cajera de un banco
- g) es agente de seguros
- h) es cajera en un banco y feminista
La tarea consistía en asignar puntuación del 1 al 8 a las afirmaciones anteriores donde 1 fuera la afirmación más probable y 8 la menos probable. La descripción de Linda fue diseñada para ser muy representativa de una feminista activa (c) y muy poco de cajera de banco (f), por lo que se esperaba que considerasen más representativa de la personalidad de Linda la conjunción (h) que el componente menos representativo de la conjunción (f). El porcentaje de participantes que mostró orden predicho (c > h > f), fue del 85%. La violación de la regla de conjunción es la comparación directa entre f y h (falacia de la conjunción).
Según Teversky (1977), la semejanza de un ejemplar con una categoría se define en función de la ponderación de las propiedades que son comunes y distintivas y esta ponderación varía en función del contexto estimular y la tarea experimental. En la descripción de Linda, la ponderación con una cajera de banco es baja. El hecho de añadir feminismo como rasgo distintivo explica la forma en que los participantes ordenaron la lista de afirmaciones sobre las actividades que desarrolla ella, en función del grado con el que encajaban con el estereotipo que se deriva de la descripción. Desde el punto de vista de la regla extensional de la Lógica, la clase “cajeras de banco” incluye a la de “Cajeras de banco feministas”, lo que invalida desde un punto de vista normativo el juicio probabilístico emitido por los participantes, que invierte la relación probabilística de ambas clases. El heurístico de representatividad explica dicha inversión.
Tversky y Kahneman (2002), se plantearon si los participantes podrían reconocer la validez de la regla de conjunción si se expresaba el problema de forma explícita. Después de la misma descripción inicial se recibían las afirmaciones f) (Linda es cajera de un banco) y h) (Linda es cajera de un banco y feminista) en forma de argumentos 1 y 2, respectivamente:
- Argumento 1: Es más probable que Linda sea cajera en un banco a que sea cajera en un banco y feminista, puesto que todas las cajeras de banco feministas son cajeras de banco mientras que algunas cajeras de banco no son feministas, y Linda podría ser una de ellas.
- Argumento 2: Es más probable que Linda sea cajera en un banco y feminista a que sea cajera en un banco, puesto que se parece más a una feminista que a una cajera de banco.
La mayoría de los participantes eligieron el argumento no válido del parecido frente al argumento extensional válido. Esto explica que aún cuando se induce una actitud reflexiva no elimina el atractivo del heurístico de representatividad. Otros estudios sobre el tema, proporcionando cuestionarios con preguntas sobre razonamiento probabilístico previo a la tarea, o bien incluso investigando en dominios específicos y con expertos, los resultados siguen siendo consistentes con el heurístico de representatividad.
Heurístico de accesibilidad
Las personas evaluamos la frecuencia de los ejemplares de una categoría o probabilidad de un acontecimiento por la facilidad con la que los ejemplos nos “vienen a la mente” o se “nos ocurren”. Evaluamos por ejemplo el riesgo de sufrir un infarto más probable en personas de entre 50 y 60 años. Los ejemplos de categorías más frecuentes se recuerdan más fácil, y rápido, pero muchas veces esta accesibilidad se ve afectada por otro tipo de factores, produciéndose sesgos que Teversky y Kahneman (1973) agrupan en cuatro categorías diferentes.
Sesgo debido a la facilidad de recuperación
Tversky y Kahneman (1973) presentaron a las participantes listas grabadas con 39 nombres. En una condición experimental la lista incluía 19 nombres de mujeres famosas y 20 nombres de hombres menos famosos (lista 1). La otra condición experimental consistía en 19 nombres de hombres famosos y 20 nombres de mujeres menos famosas (lista 2).
La fama y la frecuencia en función del sexo estaban inversamente relacionadas en ambas listas. Los participantes se dividieron en dos grupos:
- Grupo 1 se les pidió que recordaran el mayor número de nombres que pudieran de cada lista.
- Grupo 2 se les pidió que juzgaran para cada una de las dos listas si contenían más nombres de hombres o mujeres.
Los resultados obtenidos en ambos grupos fueron de idéntico signo para las listas 1 y 2. Los participantes del grupo 1 recordaron más nombres de mujeres de la lista 1 y más nombres de hombres de la lista 2, lo que indica que fue la fama y no la frecuencia objetiva lo que determinó la facilidad de recuerdo. En coherencia con este resultado, los participantes del grupo 2 estimaron que la lista 1 contenía más nombres de mujeres que de hombres mientras que la lista 2 contenía más nombres de hombres, en contra también de la frecuencia relativa real.
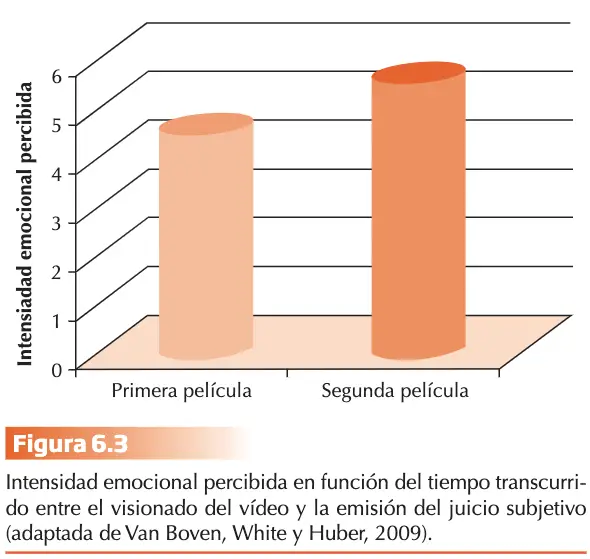
El sesgo observado demostró el efecto significativo del heurístico de accesibilidad en el juicio probabilístico. Además de la familiaridad, estaría la saliencia. La probabilidad subjetiva de accidentes de tráfico aumenta temporalmente si acabamos de ver un coche volcado en la carretera. Este sesgo de inmediatez se basa en la facilidad de recuperación de las experiencias recientes frente a las remotas. Otro resultado consolidado es el de la investigación en la auto-percepción de estados emocionales, pues parece que se perciben como más intensas las emociones previas e inmediatas. Son juzgadas así desde el punto de vista fenomenológico, sensitivo e informativo.
El experimento de Van Boven, White y Huber (2009) corrobora esta hipótesis. Los participantes observaron dos secuencias de películas de dos minutos de duración separadas por un periodo de veinte minutos. Ambas películas mostraban atrocidades con contenidos genocidas. Se contrabalanceó el orden de presentación de las películas entre los participantes. Después de observar la segunda película, se pidió a los participantes que juzgaran la intensidad de sus estados emocionales para cada una de las dos películas en una escala de 7 puntos (1 =no intensa, 7=extremadamente intensa). Los participantes exhibieron un sesgo de inmediatez informando que su reacción emocional ante la segunda película era significativamente más intensa que la reacción emocional a la primera película.
Sesgo debido a la facilidad en la construcción de ejemplos
Teversky y Kahneman (1973) facilitaron una regla al participante para la construcción de ejemplos de 2 categorías y les pidieron que estimaran su frecuencia relativa. El participante no podía enumerar todos los ejemplos posibles, pero sí intentaba buscar algunos ejemplos y juzgar la frecuencia de cada categoría por la accesibilidad relativa de éstos. En un experimento se seleccionaron consonantes que en inglés son más frecuentes en la tercera posición de una palabra (K, L,N,R, y V).
El problema se planteaba al participante de la forma siguiente:
- La letra (L) aparece con mayor probabilidad en:
- – ¿la primera posición?
- – ¿la tercera posición?
- Mi estimación de la proporción de estos dos valores es: … / …
La frecuencia estimada fue significativamente mayor para la primera posición en las cinco letras estudiadas, demostrando sesgo en la estimación de la frecuencia relativa debido a la superior facilidad de generar ejemplos que empiecen con una letra determinada frente a los que la contienen en tercera posición. Posteriormente bajo condiciones más estrictas de control y alguna modificación, se manipularon el valor informativo o diagnóstico de la experiencia subjetiva de accesibilidad generando en los participantes a través de las instrucciones la atribución errónea de la experiencia de facilidad de recuperación:
- Todos los participantes escribieron en un folio en blanco 10 palabras que contenían la letra “t” en la tercera posición.
- Los grupos se diferenciaron en la manipulación experimental del valor diagnóstico de la experiencia de facilidad de recuperación de las palabras que empezaban por la letra “t”:
- 1. El grupo “facilitación”, debía escribir las 10 palabras que empezaban por “t” sobre un folio con filas de pequeñas letras “t” impresas en color pálido. A este grupo se le informó que la impresión de estas letras facilitaría la tarea de recuerdo.
- 2. El grupo “inhibición”, debía escribiría 10 palabras que empezaban por “t” sobre el mismo tipo de folio pero se le indicó que esto dificultaría su tarea de recuerdo.
- 3. El grupo de “control”, realizó la tarea sobre folio en blanco.
- Todos los participantes valoraron el grado de dificultad de una y otra tarea de entre 1 (muy fácil) y 8 (muy difícil) inmediatamente después de realizar cada una de ellas.
- Los juicios de frecuencia de palabras que empiezan por “t” respecto a los que la contienen en la 3ª posición se realizaron concluidas ambas tareas, emitiendo en escala de 8 puntos, donde: o 1 = muchas más palabras con t en tercer lugar que palabras que empiezan por “t”. o 8 = muchas más palabras que empiezan por “t” que palabras con ten tercer lugar.
Todos los sujetos (independientemente de la condición experimental) informaron que les resultaba más difícil recordar palabras que la tienen en la tercera posición. El efecto de la manipulación del valor diagnóstico de la experiencia de recuperación produjo un impacto significativo en los juicios de frecuencia relativa de los participantes. Unos creían que la hoja facilitaba y emitieron juicio bajo de frecuencia relativa de las palabras que empezaban por “t”; los del grupo de inhibición, creyeron que su ejecución había sido inhibida y aportaron el juicio más alto de frecuencias relativas de las palabras que empiezan por “t”. El juicio estimado de los participantes del grupo de control se situó entre estos dos valores.
Estos resultados demuestran que la experiencia fenomenológica o subjetiva de facilidad o dificultad en la recuperación de la fuente de información determina la estimación de la frecuencia relativa en los juicios. Cuando esta experiencia subjetiva pierde versus gana valor diagnóstico, la frecuencia relativa estimada disminuye versus aumenta en coherencia. De acuerdo con Wanke y cols., estos resultados confirman y amplían conceptualmente la interpretación de Tversky y Kahneman (1973) del heurístico de accesibilidad. La estimación de frecuencias relativas se basa no sólo en la experiencia subjetiva de facilidad de recuperación sino también en el grado de confianza que el sujeto atribuye a dicha experiencia.
A destacar también los contextos donde se hace la tarea de búsqueda. Los contextos de palabras abstractas como igualdad, justicia, … resultan más fáciles de imaginar o asociar a historias vividas, leídas o basadas en películas que palabras concretas (p. ej., Constitución o Convenio) desprovistas de connotaciones que permitan evocar con facilidad escenarios.
Sesgo debido a la facilidad para imaginar situaciones
La facilidad para imaginar es importante en la evaluación de probabilidades en la vida real. El riesgo que entrañe una jornada reivindicativa (p. ej., 8M) manifestación, se evaluará en función de la facilidad para imaginar de forma vívida con posibles contingencias peligrosas (una carga policial, un atentado machista, la posibilidad de ser contagiado por el COVID 19, un meteorito, etc.), aunque la facilidad con que se imaginan los posibles desastres no refleje el riesgo real. Asimismo, el riesgo puede ser subestimado si posibles peligros reales son difíciles de concebir o simplemente no acceden a la mente.
Sherman, Cialdini, Schwartzman y Reynolds (2002) pusieron a prueba esta hipótesis. Los participantes asignados al grupo de control (sólo lectura) leyeron un informe sobre una supuesta enfermedad (hiposcenia-B). En la condición “fácil de imaginar” los síntomas de la enfermedad eran concretos y probablemente experimentados por una gran mayoría de los participantes (cansancio, dolor muscular, dolores de cabeza frecuentes, etc.). En la condición “difícil de imaginar” los síntomas eran mucho menos concretos (sensación vaga de desorientación, mal funcionamiento del sistema nervioso e inflamación del hígado). Los participantes asignados al grupo experimental (lectura+ imaginación) fueron también asignados o bien a la condición “fácil de imaginar” o “difícil de imaginar”. En la condición “fácil de imaginar”, a los participantes se les indicó que debían leer el informe mientras imaginaban cómo sufrían los síntomas de la enfermedad durante un periodo de tres semanas. A continuación, se pidió a todos los participantes que juzgaran la probabilidad de sufrir hiposcenia-B en el futuro en una escala de 10 puntos que iba desde muy probablemente (1) hasta muy improbablemente (10).
Los resultados mostraron que los participantes del grupo “imaginación” mostraron una tendencia a juzgar la probabilidad de contraer la enfermedad en la condición “fácil de imaginar” superior a la del grupo de control, y una tendencia a juzgar la probabilidad de contraer la enfermedad en la condición “difícil de imaginar” inferior a la del grupo de control.

Sesgo debido a la correlación ilusoria e ilusión de control
Las asociaciones entre eventos se fortalecen como resultado de la ocurrencia conjunta repetida. Esto determina que juzguemos la frecuencia de ocurrencia conjunta de los que están asociados en proporción elevada. Sin embargo, este tipo de estimaciones tampoco escapa a la posibilidad de sesgos en el juicio probabilístico.
El término correlación ilusoria propuesto por Chapman (1967), agrupa los errores que se producen como resultado de la sobreestimación de la correlación entre dos eventos. En los experimentos de Chapman los participantes recibían pares de palabras proyectadas en una pantalla. Unas a la derecha (huevos, tigre o cuaderno) y otras a la izquierda (beicon, león, flor, barca) y se agrupaban al azar. Los participantes sobreestimaron la frecuencia de aparición de los pares semánticamente relacionados como: beicon-huevos o león-tigre. La relación semántica entre esas palabras explica la fuerza de asociación en la memoria y la facilidad para su recuperación, lo que lleva a sobreestimar la frecuencia objetiva.
La correlación ilusoria es uno de los mecanismos en que se basa la explicación del origen de las supersticiones o las creencias mágicas, el “efecto de halo” y los estereotipos sociales. Sobreestimar la correlación que existe entre dos factores distintivos, p. ej., cometer delitos y pertenecer a un grupo minoritario, contribuye a generar estereotipos negativos sobre estos grupos (Mullen y Johnson, 1990).
Cuando se sobreestima la correlación entre la conducta y sus consecuencias se produce “ilusión de control” (expectativa de probabilidad de éxito personal inadecuadamente elevada con relación a la probabilidad objetiva). Langer (1975) demostró en unos experimentos en los que simuló distintos tipos de azar induciendo factores supuestamente relacionados con la habilidad y destreza del jugador, como son la competitividad, la posibilidad de elegir, la familiaridad con los estímulos y las respuestas y la implicación pasiva o activa en la situación. Este fenómeno es uno de los factores que explica el sentimiento excesivo de confianza en el éxito y el riesgo excesivo asumido en los juegos de azar. Contribuye además a explicar la persistencia de este sesgo en la sobreconfianza en la calibración del propio juicio (juicio de segundo orden).
Heurísticos del prototipo
Kahneman y Frederick (2002; 2005) han utilizado el término “Heurístico del prototipo” enmarcándolo en el enfoque del juicio heurístico dentro de un modelo más integrador que el inicial presentado. Parece ser que estos heurísticos son el resultado de un doble proceso de sustitución:
- Una categoría se sustituye por su ejemplar prototípico.
- Un atributo de la categoría (el que se evalúa en el juicio emitido) se sustituye por una propiedad del prototipo.
P. ej., cuando un participante juzga la probabilidad de que Linda sea cajera de banco (frente a cajera de banco y feminista) está llevando a cabo dos procesos de sustitución. Sustituye la categoría “cajera de banco” por su ejemplar prototípico, para después sustituir el atributo de probabilidad de la pertenencia de Linda a la categoría por la propiedad de semejanza de Linda con el prototipo. Desde el modelo normativo de la Teoría de la probabilidad, la probabilidad de pertenencia debería variar con la probabilidad a priori de la categoría. Por el contrario, en la predicción por representatividad de la pertenencia de un ejemplar a una categoría se descarta la probabilidad a priori porque el prototipo de una categoría no contiene información sobre la frecuencia de sus miembros.
La novedad del enfoque integrador de Kahneman y Frederick (2002) se concreta en que la representatividad no es necesariamente la propiedad del prototipo que sustituye al atributo de la categoría. En un estudio se presenta una doble pregunta:
- ¿Cómo te sientes de feliz con tu vida en general?
- ¿Cuántas citas románticas has tenido durante el último mes?
Strack, Martín, y Schwarz (1988) demostraron que la correlación entre estas dos preguntas fue insignificante cuando se plantearon en este orden y alcanzó el valor de 0.66 cuando se invirtió el orden de presentación de las preguntas. En este caso, el número de citas en el último mes difícilmente puede considerarse representativo del sentimiento global de felicidad, pero la accesibilidad de la información le confiere una saliencia y un peso relativo elevados.
La evaluación retrospectiva de las experiencias con valor afectivo ilustra bien el doble proceso de sustitución basado en la accesibilidad de la información. Esta evaluación se basa fundamentalmente en el promedio entre la media del pico más saliente de la experiencia global y el pico más próximo al final de la experiencia.
Redelmeier y Kahneman (1996) registraron el nivel de dolor informado cada 60 segundos en una prueba de colonoscopia. Dicha prueba duraba entre 4 y 69 minutos. Se tenía paciente A y B, y los resultados demostraron que la evaluación restrospectiva del dolor producido por la prueba, podía predecirse con un grado considerable de eficacia promediando el pico más elevado con la magnitud de dolor que había producido el momento final de la experiencia. “A” informó que había sido mucho más desagradable pero el pico máximo no se diferenció entre ambos sujetos y el participante “B” soportó una prueba más prolongada. Lo que ocurre es que el valor afectivo de la experiencia para el “A” quedó determinado por ser este pico alto próximo al final de la prueba. Redelmeier, Katz y Kahneman (2003) demostraron que el simple hecho de añadir al final de la experiencia un intervalo corto de malestar mínimo produjo en los pacientes una evaluación global de la experiencia como menos aversiva e incrementó el número posterior de pruebas de seguimiento.
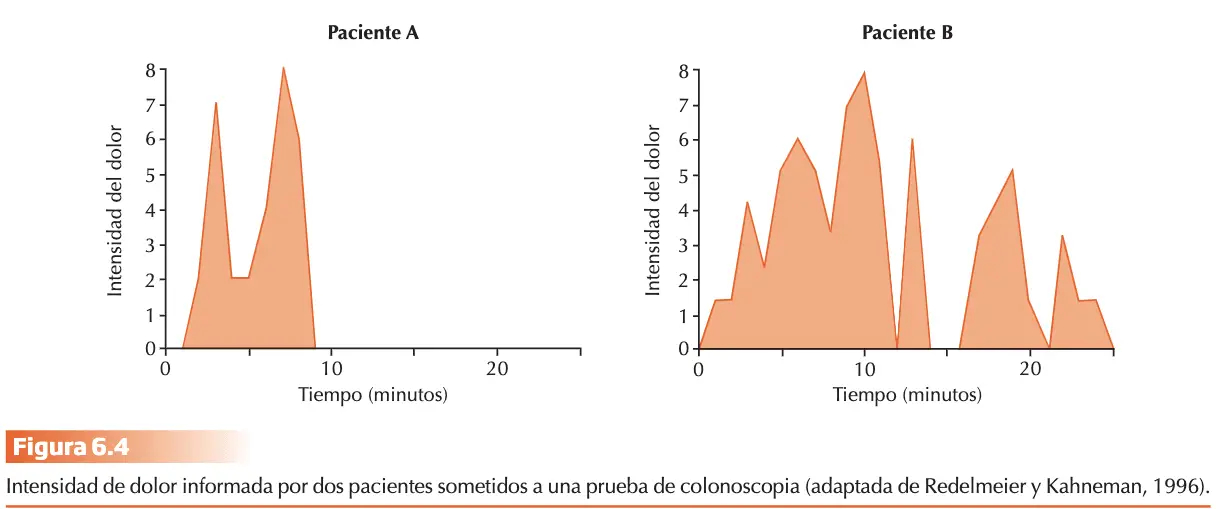
Un doble proceso de sustitución da lugar al heurístico de prototipo que determina el juicio subjetivo del sujeto. La categoría “dolor que produce la experiencia global” se sustituye por el prototipo “promedio del pico más elevado de dolor y del valor más próximo al final de la experiencia”. Pero en este caso la propiedad del prototipo no viene dada por la representatividad de la información (duración total de la experiencia o magnitud promedio del dolor global) sino por su accesibilidad en la memoria.
La insensibilidad a características extensionales de las categorías (las probabilidades a priori en la predicción de la pertenencia de un ejemplar a una categoría o la relación monotónica entre la duración de la experiencia y su valor afectivo) constituye ejemplos de la desviación sistemática del modelo normativo de la lógica en el juicio intuitivo bajo incertidumbre. El proceso común de sustitución del atributo de la categoría por una propiedad del prototipo se demuestra en variedad de dominios e indica que los juicios complejos se sustituyen por valoraciones semánticamente más simples y accesibles. El ejemplo del “dolor”, constituye la estimación cuantitativa subjetiva de una experiencia con valor afectivo.
Heurístico de anclaje y ajuste
Circunstancialmente realizamos estimaciones de cantidades a partir de un valor inicial que se va ajustando hasta la respuesta final. El valor inicial puede sugerirse por la formulación del problema o ser el resultado de un cómputo parcial. En uno u otro caso, diferentes puntos de partida producen estimaciones diferentes sesgadas hacia el valor inicial. Tversky y Kahneman (1974) pidieron a los participantes estimar el porcentaje de países africanos de Naciones Unidas. El valor inicial (entre 0 y 100) se establecía haciendo girar una rueda de fortuna en su presencia.
El experimento se desarrolló en 2 fases:
- 1º fase de juicio comparativo: estimar si el porcentaje era superior o inferior al resultado del giro de la rueda.
- 2º fase de juicio absoluto: se pedía establecer el porcentaje concreto requerido.
La mediana de las estimaciones para valores iniciales de 10 y 65, fueron de 25 y 45 respectivamente, demostrando el efecto del valor de partida en la respuesta final. Los iniciales eran producto de azar, y estos valores numéricos informativos pueden servir como anclajes. El participante basa su estimación en un cómputo inicial incompleto. Tversky y Kahneman (1974) pidieron a un grupo de estudiantes estimar en 5 segundos el siguiente producto:
8x7x6x5x4x3x2x1
Y a un segundo grupo el producto:
1x2x3x4x5x6x7x8
La mediana de la estimación en secuencia descendente fue de 2.250 y para la ascendente de 512. El valor real es 40.320. El producto de los primeros números constituye la información de anclaje que explica el valor estimado en el juicio absoluto. En la fase comparativa se genera una estimación de la cantidad independiente del valor de anclaje y compara este valor con su estimación para determinar si el anclaje es demasiado alto o bajo. Para emitir el juicio absoluto, ajusta el juicio inicial en la dirección apropiada hasta encontrar el valor más aceptable. Este proceso de ajuste es insuficiente porque termina el límite más próximo al valor del ancla dentro del rango de valores posibles.
Los resultados del estudio de Jacowitz y Kahneman (1995) cuestionan esta interpretación. En su estudio los valores de anclaje proporcionados se basaron en las estimaciones de 15 problemas de juicio cuantitativo obtenidas en un grupo de sujetos que no participaron en el experimento de estimar altura del monte Everest, la distancia entre San Francisco y Nueva York, o el número de profesoras en la Universidad de Berkeley. Los valores de anclaje correspondían al percentil 15 y 85 de este grupo como anclas de valor bajo frente a alto. Los autores demostraron un efecto asimétrico en el sesgo de anclaje. Este fue significativamente superior para los valores elevados. Y se vio reforzado por el hecho de que un porcentaje de sujetos (27%) superior al grupo de 15% inicial, generaron juicios cuantitativos superiores al valor del percentil 85 y no fue así con el porcentaje de sujetos (14%) que generaron juicios inferiores al del percentil 15 del grupo inicial. Los valores de anclaje altos incrementan la plausibilidad de los valores superiores al ancla en mayor medida que los bajos incrementan la plausibilidad de los valores inferiores al ancla, siendo la razón de que 0 es el límite, pero no se da límite superior (infinito). Según los autores, se pone de manifiesto que el sesgo no siempre se da en el proceso de ajuste de la estimación inicial, puesto esta ancla puede alterar la creencia inicial del individuo y modular el juicio absoluto emitido. Por tanto, se sugiere que este proceso de anclaje se inicia en la fase de comparación y sesga la estimación inicial del sujeto, previa al juicio absoluto. Jacowitz y Kahneman (1995) concluyen enumerando tres posibles causas del anclaje en tareas de juicio cuantitativo, que no deben considerarse mutuamente excluyentes.
El ancla puede considerarse:
- Un punto de partida para el ajuste (formulación inicial de Tversky y Kahneman (1974).
- Un indicio conversacional, debido a la saliencia que le confiere la autoridad académica del experimentador.
- Una sugerencia o prime.
En la línea de los resultados de Jacowitz y Kahneman, la investigación más reciente sugiere que el anclaje se origina con frecuencia en la fase de recuperación de la información y que el ancla actúa como una sugerencia, haciendo la información consistente con el ancla más accesible. En apoyo de esta interpretación, se demuestra que el efecto de anclaje no se produce si no se cumplen determinadas condiciones de compatibilidad entre el ancla (valor inicial) y el juicio requerido (respuesta final), como es la escala de medida en la que se formulan ambos.
El trabajo de Strack y Mussweiler (1997) demuestra que, además, es necesario que se expresen en la misma dimensión (altura frente anchura). Estos autores utilizaron cuatro condiciones experimentales.
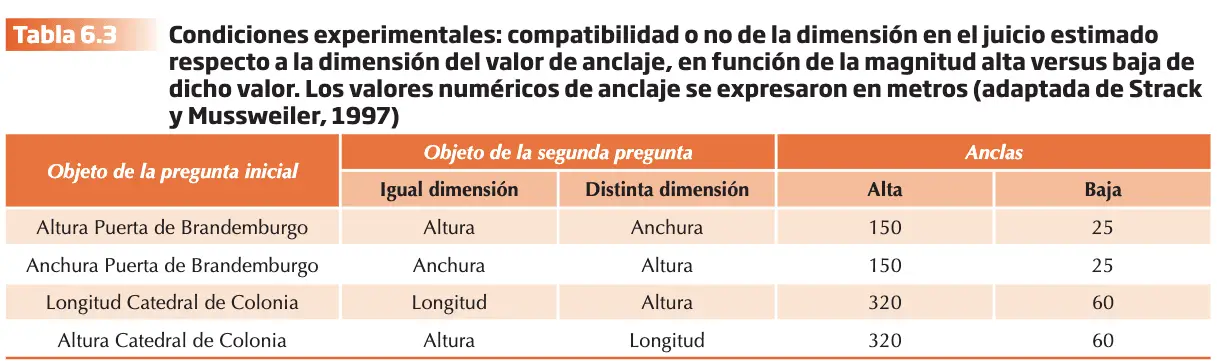
A los participantes se les formularon dos preguntas. En la primera se les pedía un juicio comparativo considerando valor del ancla “mayor o menor que”, y en la segunda un juicio absoluto. Se utilizaron cuatro condiciones 2 x 2 (compatibilidad o no de la dimensión del ancla con la dimensión del juicio; y valor del ancla alto frente a bajo). La interacción reveló que el efecto de anclaje solo fue significativo cuando las dimensiones fueron iguales solo cuando el valor del ancla fue elevado. El hecho de que el efecto de anclaje disminuya de forma significativa cuando la dimensión del juicio difiere de la del ancla, no puede explicarse por el priming numérico que proporciona el ancla. Sugieren los resultados que la fuerza del efecto depende de la medida en que la información es activada por el ancla también se percibe como aplicable al juicio absoluto.
Strack y Mussweiler 1997 terminan su investigación con otro experimento que permite poner a prueba la hipótesis del priming semántico y no el numérico por sí mismo, es el responsable de los efectos de anclaje. Utilizaron cuatro condiciones experimentales, un 2 x 2 (ancla plausible / no; ancla alta frente a baja).
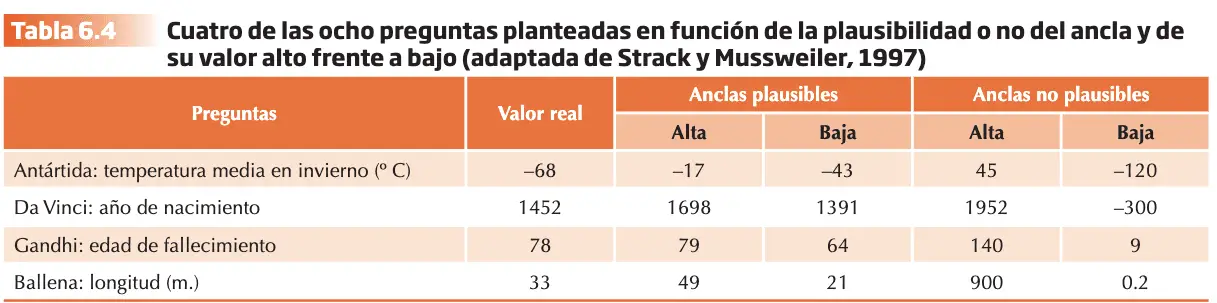
Como variables dependientes se registraron valores de juicios y la latencia de respuesta en los dos juicios (comparativo y de valor absoluto). El análisis de la latencia desvela algo interesante:
- Las latencias (tiempos) fueron significativamente mayores para las anclas plausibles frente a las no plausibles, mientras que en los juicios absolutos este patrón fue al revés.
- Los datos sugieren que cuando el ancla es un valor plausible, los participantes resuelven la tarea comparativa elaborando la respuesta en un proceso cognitivo que consume tiempo. La información relevante es fácilmente accesible y acelera la respuesta en la tarea de juicio absoluto posterior. Cuanto más tiempo consuma el juicio comparativo menos tiempo consumirá el juicio absoluto.
- Las latencias en ambos juicios deberían estar inversamente correlacionadas, pero sólo en la tarea comparativa cuando se utilice información relevante.
- En el caso de las anclas plausibles, ambas latencias de respuesta correlacionaron de forma negativa y significativa de tal forma que las latencias más largas en el juicio comparativo implicaban latencias más cortas en el juicio absoluto. Para las anclas no plausibles, sin embargo, las latencias de respuesta de ambos juicios no correlacionaron.
Chapman y Johnson (2002) presentan modelo alternativo a la propuesta de Tversky y Kahneman (1974), que permite interpretar el sesgo de anclaje en amplio abanico de tareas y procedimientos experimentales. El mecanismo se basa en proceso de accesibilidad selectiva que se genera en la fase de recuperación de la información y determina la formación de la respuesta. Este proceso es el resultado de múltiples causas y los mecanismos responsables pueden producirse en más de una fase. Los sesgos y errores se producen a consecuencia del priming asimétrico en el proceso de recuperación de la información, incrementando desproporcionadamente la disponibilidad de rasgos compartidos por “ancla” y respuesta y reduciría la disponibilidad de aquellos rasgos que los diferencian.
Imaginemos que has vivido toda tu vida en Xixón y un día por circunstancias de la vida te trasladas a vivir a Madrid, caes enfermo y tiene que acudir al médico. El SESPA podrían servir para valorar la calidad de la sanidad madrileña y ajustarla luego según la diferencia en calidad. El proceso de anclaje es, en este caso, equilibrado e ilustra la funcionalidad del heurístico como recurso rápido que implica un esfuerzo cognitivo mínimo. Imaginemos, como estrategia alternativa, que tiene que ser tratado de un cáncer de testículos, pero en lugar de tratarlo en la sanidad pública Madrileña se trata en la prestigiosa y carísima clínica Ruber de Madrid. Obviamente, si activamos los rasgos compartidos (sistema de salud) en detrimento de los rasgos que diferencian ambos (sanidad privada frente a sanidad pública) nuestra estimación será excesivamente elevada y estaremos cometiendo un sesgo en la valoración. A diferencia del enfoque del efecto de anclaje como ajuste insuficiente determinado por el valor del ancla, el modelo de accesibilidad selectiva atribuye el sesgo en el juicio absoluto a una ponderación excesiva de los rasgos comunes entre el ancla y la respuesta en detrimento de los discrepantes, basada en una tendencia confirmatoria.
Si el ancla produce efecto sobre el juicio incrementando la accesibilidad de rasgos comunes y reduce a los diferentes, el hecho de incrementar experimentalmente la accesibilidad de rasgos diferentes debería reducir el sesgo hacia el valor inicial. Chapman y Johson (1999) pidieron a unos estudiantes que predijeran sobre las siguientes elecciones presidenciales en EEUU.
- 1º Debían escribir los dos últimos dígitos del nº de la seguridad social y considerarlo como una probabilidad.
- 2º Se les pide que pensaran en la probabilidad de que el candidato republicano ganara las elecciones presidenciales y que compararan su respuesta con el número apuntado. Esta primera estimación de probabilidad no se registró, para que se consideraran los dígitos como valor de anclaje. Las probabilidades de anclaje fluctuaron de 0 a 99% con una media de 48% y una mediana de 51%.
- 3º Asignar a los sujetos aleatoriamente a una de tres condiciones experimentales:
- Condición “a favor”: escribir razón por la que el republicano debía ganar.
- Condición “en contra”: escribir razón por la que el republicano no debería ganar.
- Condición “neutral”: no se les pidió escribir.
- 4º Se les pide una segunda estimación por escrito de que el candidato republicano ganara las elecciones. Se establecieron tres categorías de participantes:
- 1. SIMILAR: los de razón a favor con valores de anclaje SUPERIOR al 50% y aquellos en contra con anclaje INFERIOR al 50%
- 2. DIFERENTE: los de razón a favor con anclaje INFERIOR al 50% y aquellos en contra con anclaje SUPERIOR al 50%
- 3. NEUTRAL: los del grupo neutral.
Los resultados confirmaron la hipótesis de partida demostrando que el efecto de anclaje fue significativo sólo para las condiciones “similar” y “neutra”, y el sesgo de anclaje puede reducirse o eliminarse propiciando que los participantes identifiquen razones discrepantes con el valor del ancla.
Según Epley y Gilovich (2001), los procesos implicados en el efecto de anclaje difieren dependiendo de si el ancla es suministrada por el experimentador o por cualquier otra fuente externa, o bien es por el propio participante a partir de las preguntas planteadas. En este caso, el proceso de ajuste sería el responsable del efecto en la medida en que el valor numérico del ancla, por su condición de respuesta autogenerada, adquiriría el estatus de respuesta candidata con el peso específico suficiente para iniciarlo.
Para poner a prueba esta hipótesis, los autores compararon dos condiciones experimentales: “el valor del ancla lo genera el participante” frente a “el valor del ancla lo proporciona el experimentador”. Las respuestas fueron grabadas, transcritas y evaluadas por dos jueces. Para cada respuesta el juez evaluaba si el participante conocía el valor del ancla, si utilizaba esta como base de la respuesta y si mencionaba el ajuste a partir del valor del ancla para alcanzar la estimación final. El acuerdo entre estos era alto (0.94) y consideraron que los sujetos habían utilizado el mecanismo de anclaje y ajuste si sus informes verbales se referían tanto al ancla como al proceso de ajuste. A los que se les proporcionó utilizaron menos el mecanismo de ajuste a partir del ancla que aquellos que habían generado de forma espontánea el valor inicial.
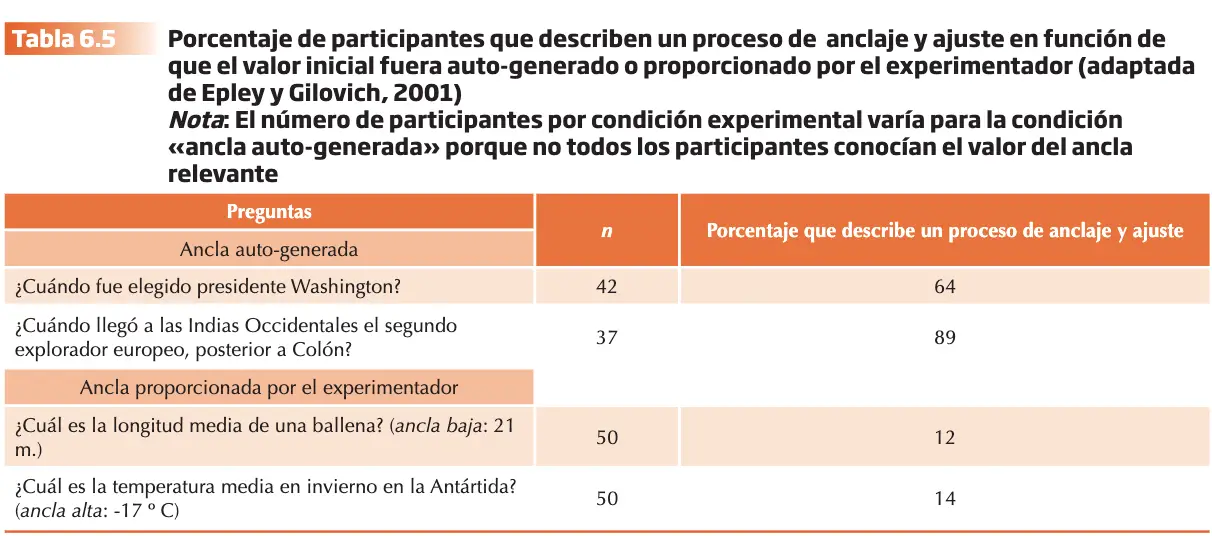
Epley y Gilovich 2001, coincidieron con Jacowitz y Kahneman proponiendo una taxonomía de posibles efectos de anclaje en los juicios bajo incertidumbre en la medida en que son muchas las variables que pueden intervenir en función de la tarea o experimento. Los resultados de la investigación que hemos recogido en este apartado nos permiten señalar algunas de ellas: la magnitud del valor del ancla, alto frente bajo, la compatibilidad o no de la escala de media y dimensión del ancla y el juicio absoluto, el grado de plausibilidad del ancla, y el hecho de que el ancla sea generada de forma espontánea por el participante o comunicada por el experimentador.
La teoría del apoyo
La teoría del apoyo constituye una perspectiva del juicio intuitivo bajo incertidumbre que permite explicar, bajo un marco teórico integrador, gran parte de la evidencia revisada en el apartado previo, que caracteriza las operaciones mentales que responden a la denominación del juicio basado en heurísticos en la evaluación de frecuencias y probabilidades (Brenner, Koehler y Rottenstreich, 2002). El efecto de desempaquetado es el principio explicativo de esta teoría, el cual quiere demostrar que “el todo es menor que la suma de sus partes”. Las descripciones detalladas de un acontecimiento determinado dan lugar, de forma sistemática, a juicios de probabilidad superiores que las que genera una descripción general del mismo acontecimiento. P. ej., un acontecimiento especifico “1000 personas morirán en un terremoto”, se juzga como como más probable que un evento más inclusivo “1000 personas morirán en un desastre natural”.
Tversky y Koehler (1994) desarrollaron una teoría no extensional en la cual la probabilidad subjetiva no está ligada a los acontecimientos, sino a las descripciones de estos, denominadas hipótesis. La evidencia empírica demuestra que el juicio probabilístico sobre un evento determinado depende del grado en que se explicita su descripción. Cada hipótesis A, posee un valor de apoyo determinado, s(A), que corresponde a la fuerza de la evidencia favorable a dicha hipótesis. La clave es que desempaquetar la descripción de una hipótesis en sus posibles componentes o hipótesis elementales generalmente aumenta su apoyo. Así, el apoyo de la disyunción explícita Ca ? Cn es igual o mayor que el apoyo de la disyunción implícita, C, que no menciona ninguna causa. Por tanto:
?(?) ? ?(?? ? ??)
La Teoría del apoyo es subaditiva para disyunciones implícitas (C), y aditiva para las disyunciones explícitas (Ca V Cn):
?(?? ? ??) = ?(??) + ?(??)
El grado de subaditividad es influido por varios factores, uno es la interpretación de la escala de probabilidad, será pronunciada cuando la probabilidad se interpreta como la predisposición de un caso individual respecto a cuando se estima como frecuencia relativa en una determinada población. Kahneman y Tversky (1982) denominan a estas dos modalidades de juicio singular y distribucional y que es más preciso el segundo. Esta propuesta indica que la disyunción implícita “accidente” se desempaqueta con mayor facilidad en sus componentes (p. ej., accidente de coche, de avión, fuego, envenenamiento…) cuando se considera a la población en su conjunto frente a una persona particular. Las posibles causas de muerte se representan en las estadísticas de mortalidad de la población, pero no en la muerte de una persona. La tendencia a “desempaquetar” una disyunción implícita es mayor en modo distribucional que en singular o individual. Cuando el problema se formula en términos de frecuencias se espera que se produzca “descuento”, es decir, menor diferencia entre la probabilidad de la hipótesis implícita y la suma de las probabilidades de las hipótesis elementales explícitas.
Tversky y Koehler (1994) pusieron a prueba el supuesto del principio del “desempaquetado”: la subaditividad para las disyunciones implícitas: ?(?) ? ?(?? ? ??).
Los participantes se dividieron en 2 grupos:
- Grupo 1: Recibió la instrucción de estimar las probabilidades de muerte para el caso de una persona determinada como consecuencia de causa específica.
- Grupo 2: Realizaron una tarea de juicios de frecuencia y evaluaron el porcentaje de personas de los 2 millones de muertes del año previo que podían atribuirse a cada una de las causas.
La tarea consistía en evaluar una hipótesis implícita (muerte como resultado de causa natural) o una disyunción explícita (muerte a consecuencia de una enfermedad cardiaca, cáncer o alguna otra causa natural), pero nunca ambas. Se definieron tres componentes y cada uno se dividía en 7 subcomponentes. Se esperaba que el hecho de explicitar en mayor medida las causas de la muerte incrementaría la subaditividad: la diferencia entre la probabilidad asignada a la hipótesis implícita y la suma de las probabilidades de los componentes de la hipótesis.
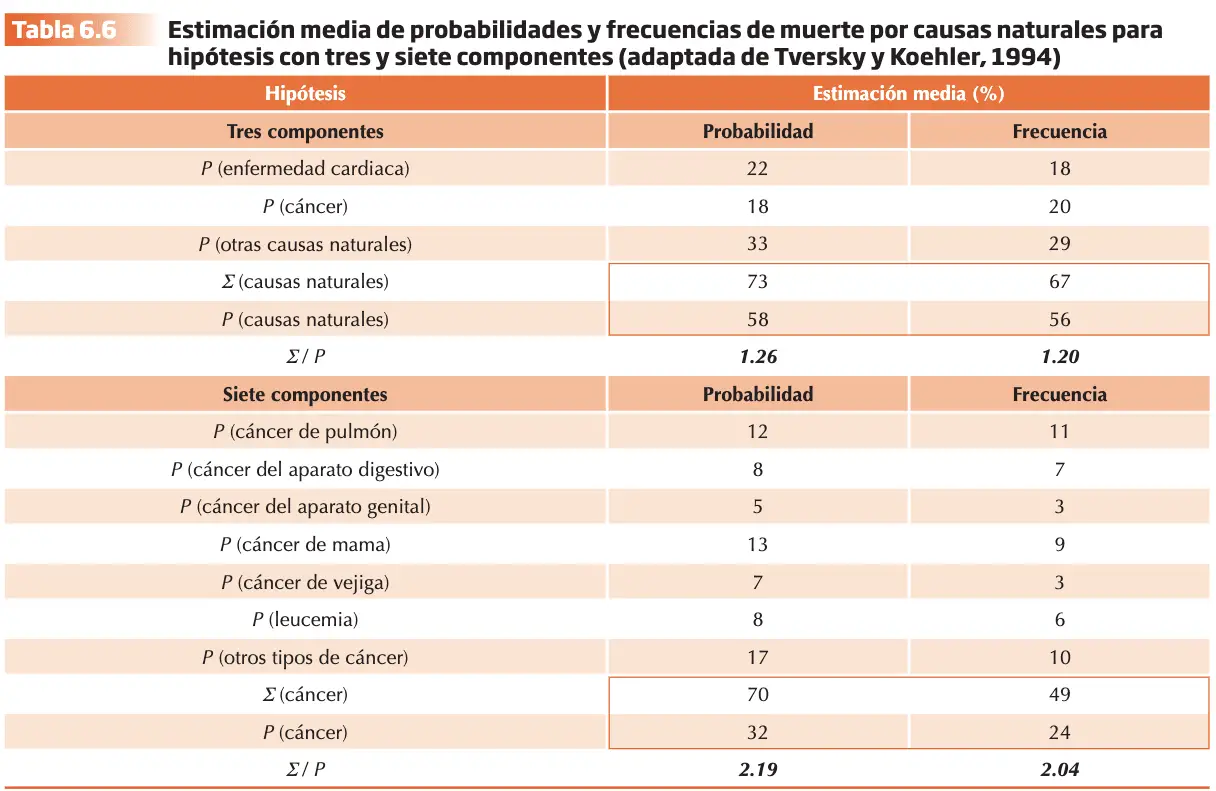
Tversky y Koehler (1994) denominaron factor de desempaquetado al índice del grado de subaditividad, calculando la ratio de las probabilidades asignadas a las hipótesis explícitas y la probabilidad asignada a la hipótesis implícita como un indicador del grado de subaditividad “factor de desempaquetado”. Este factor puede calcularse dividiendo las suma de las probabilidades de las hipótesis elementales explícitas por la probabilidad de la hipótesis implícita (?/P). Cuanto mayor sea el valor de dicho factor, mayor el grado de subaditividad observado. Siguiendo con el ejemplo anterior, hay que indicar que el grado de subaditividad aumentó con el número de componentes en la disyunción explícita (mayor grado al juzgar probabilidades que al hacerlo con frecuencias). Los resultados respaldaron la teoría del apoyo al confirmar las dos hipótesis de partida y permitieron concluir a Tversky y Koehler (1994) que la subaditividad que se observa en una disyunción implícita es tanto mayor cuanto más se explicitan sus posibles componentes y es más acusada en juicios probabilísticos frente a juicio de frecuencias.
Tversky y Koehler (1994, 2002) formulan un modelo subaditivo del juicio probabilístico para las disyunciones implícitas que contrasta con el modelo bayesiano, que asume el supuesto de aditividad. Supongamos que A1, A2 son hipótesis mutuamente excluyentes, siendo A1 ? A2 la disyunción explícita de la hipótesis implícita A. Las ecuaciones que nos permiten contrastar de forma global ambos modelos son las siguientes:
Teoría del apoyo ?(?) ? ?(?? ? ??)
Modelo bayesiano ?(?) = ?(?? ? ??)
La teoría del apoyo predice que P(A) ?P (A1 ? A2) como consecuencia del “desempaquetado” de la hipótesis implícita. Por contraste, el modelo bayesiano asume el principio de extensión en la teoría de la probabilidad, por lo que predice que P(A) = P (A1 ? A2).
El principio de extensión es posiblemente una de las reglas más simples y transparentes en la teoría de la probabilidad. Su violación es uno de los errores más llamativos y sorprendentes del razonamiento probabilístico. La regla de la conjunción es violada por la falacia de la conjunción; la regla de la disyunción, donde la probabilidad De (A o B) no puede ser inferior ni a la probabilidad de A ni a la de B porque constituye la suma de ambas. La subaditividad demostrada en el juicio probabilístico es una clara violación de la regla de la disyunción cuando no se explicitan las causas de un evento en una disyunción implícita.
Van Boven y Epley (2003) generalizaron el hallazgo de Tversky y Koehler a juicios evaluativos con valor afectivo, en los que se juzga el carácter positivo o adverso de una categoría o de las consecuencias de un acontecimiento. Los autores señalan que los factores más relevantes que explican el efecto serían las descripciones detalladas de los elementos constituyentes de una hipótesis permitiendo recordar con mayor facilidad posibilidades que han pasado por alto y facilitan la simulación mental y la imaginación vívida de las categorías o acontecimientos. Parece ser que en los juicios evaluativos de una categoría parece jugar un papel más importante la facilidad con la que se recuerdan sus elementos constituyentes que la cantidad total de elementos que pueden recuperarse.
LA TEORÍA DE LOS MODELOS MENTALES
Esta teoría ofrece un marco explicativo unitario para la deducción e inducción y sostiene que las conclusiones probabilísticas son el resultado de ambos tipos de inferencias (Johnson-Laird, 1994). Los individuos razonamos construyendo modelos de las situaciones descritas en las premisas. Una conclusión es posible si mantiene en al menos un modelo de las premisas, es probable si aparece en la mayor parte de los modelos y es necesaria si se da en todos los modelos.
Esta teoría da cuenta del razonamiento extensional sobre probabilidades (del razonamiento deductivo que genera la probabilidad de un acontecimiento a partir de las diferentes posibilidades en que puede ocurrir). Se basa en 3 principios fundamentales (que al final son 5):
- Principio de verdad. Las personas representan situaciones construyendo exclusivamente aquellos modelos mentales que responden a una posibilidad verdadera, debido a la capacidad limitada de la memoria de trabajo. Las situaciones con probabilidad 0 (corresponden a lo que es falso, por lo que, de acuerdo con la teoría, no se representan generalmente en los modelos.
- Principio de equiprobabilidad. Cada modelo representa una alternativa equiprobable, a menos que el conocimiento o las creencias de los sujetos indiquen lo contrario, en cuyo caso asignarán diferentes probabilidades a diferentes modelos
- Principio de proporcionalidad. Garantizada la equiprobabilidad, p (A)= nA/n. Si un acontecimiento, A, ocurre en cada modelo en el que ocurre otro acontecimiento, B, entonces A es al menos tan probable como B, y si, además, A ocurre en algunos modelos en los que B no ocurre, entonces A es más probable que B.
- Principio numérico. Si una premisa hace referencia a una probabilidad numérica, serán etiquetados con sus valores numéricos apropiados, y una probabilidad desconocida puede ser calculada restando la suma de las (n-1) probabilidades conocidas de la probabilidad global de la n posibilidades en la partición.
Para explicar las inferencias bayesianas en el razonamiento probabilístico se requiere, además, un quinto principio que Johnson-Laird y cols. (1999) ilustran con el ejemplo siguiente: De acuerdo con las estadísticas, 4 de cada 10 personas sufren una enfermedad, 3 de cada 4 con la enfermedad tienen el síntoma, y 2 de cada 6 sin la enfermedad tienen el síntoma. Pat es una persona seleccionada al azar y tiene el síntoma. ¿cuál es la probabilidad de que Pat sufra la enfermedad? Los sujetos ingenuos construirán los modelos mentales verdaderos y equiprobables, que serían etiquetados con sus valores numéricos apropiados.

De acuerdo con Johnson-Laird y cols. (1999) la probabilidad de que Pat sufra la enfermedad puede ser calculada a partir de la representación extensional de los modelos mentales vistos en la tabla anterior sin necesidad de utilizar el Teorema de Bayes.
- Principio del subconjunto. Suponiendo la equiprobabilidad, la probabilidad condicional p(A|B) depende del subconjunto de B que es A, y la proporcionalidad de A respecto a B da lugar al valor numérico. Si los modelos se etiquetan con sus frecuencias absolutas entonces la probabilidad condicional es igual al modelo de A y B dividido por la suma de todas las frecuencias de modelos que contienen a B (los sujetos asignan erróneamente valores al numerador o denominador).
Si se aplican correctamente este principio, serían capaces de inferir deductivamente el subconjunto A y B (enfermedad y síntoma) del conjunto apropiado B (síntoma) y resolver correctamente la inferencia bayesiana a partir del cálculo de la relación probabilística 3/5. Si los sujetos se focalizan en el modelo:
enfermedad síntoma 3
Extraerían este subconjunto erróneamente del conjunto de todas las posibilidades y afirmarían que la relación probabilística es 3/4. En este caso, los sujetos estarían no estarían atendiendo a la capacidad predictiva del dato, es decir, a la probabilidad de que el síntoma (B) se observe en ausencia de enfermedad (no A).
Giutto y Gonzalez (2001), manipularon el contenido de las instrucciones aplicando el principio del subconjunto para calcular la probabilidad condicional inversa. Para resolver problemas similares al de Pat y plantearon dos pasos pidiendo que se completaran frases como las siguientes: “Vamos a analizar cuál es el problema de que Pat sufra la enfermedad en el supuesto de que presente el síntoma. Del total de 10 posibilidades, Pat tiene ________posibilidades de tener el síntoma; entre éstas posibilidades, _________posibilidades estarían asociadas con la enfermedad.”
Las instrucciones facilitaron la respuesta correcta (de 5 posibilidades de tener el síntoma, 3 están asociadas con la enfermedad) en el 53% de los participantes, frente al 8% en la condición de control.
Los principios normativos de la inferencia bayesiana resultan frecuentemente contraintuitivos y propone una pedagogía del razonamiento bayesiano basada en la teoría de los Modelos Mentales en la que las probabilidades se planteen en términos numéricos sencillos, y así permitir la inferencia de la probabilidad condicional posterior aplicando el principio del subconjunto sin necesidad de aplicar el Teorema de Bayes.
Barbey y Sloman (2007), integran el enfoque de los modelos mentales enmarcado dentro de las hipótesis de los conjuntos anidados. Los errores y sesgos en la inferencia bayesiana se reducen de forma considerable cuando el planteamiento del problema facilita la representación de las relaciones inclusivas de las categorías relevantes para resolverlo. Según éstos el que se haga más fácil debido a la presentación de frecuencias en vez de en formato de probabilidades, se debe a que el formato de frecuencias contribuye a clarificar y hacer más transparentes las relaciones inclusivas pertinentes. Los autores presentaron mediante gráfica con círculos de Euler, el rendimiento de dos grupos de sujetos en dos versiones de un problema:
“Se ha desarrollado una prueba para detectar una enfermedad. La probabilidad de que un americano la padezca es de 1/1000. Un individuo que no padece la enfermedad tiene una probabilidad del 5% de dar positivo en la prueba. Un individuo que padece la enfermedad dará positivo en la prueba en todos los casos. ¿Cuál es la probabilidad de que una persona extraída al azar que dé un resultado positivo padezca realmente la enfermedad? __ %”
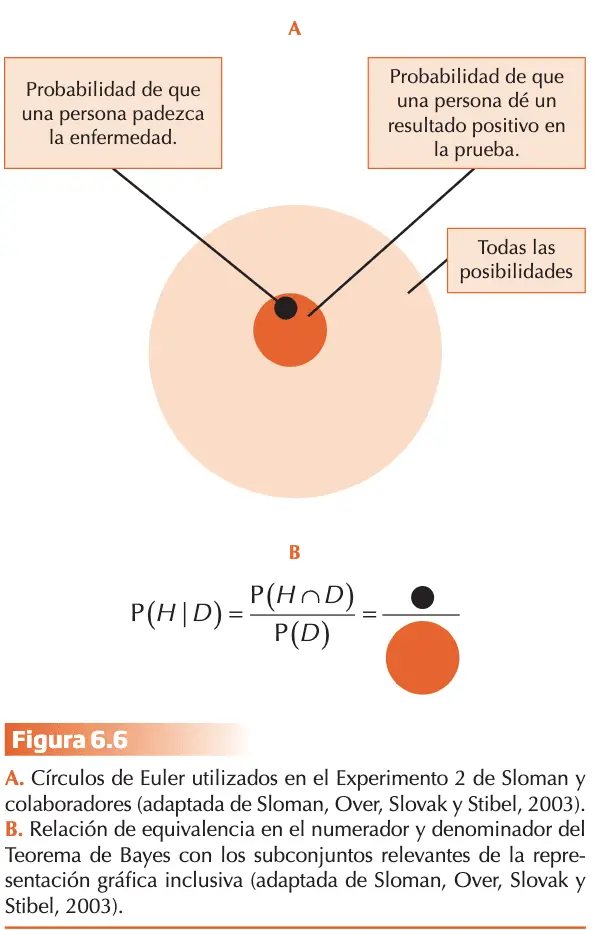
La respuesta más frecuente con este tipo de versión es 95% suponiendo que el error de la prueba sea un 5% (falsos positivos), debería producir un 95% de resultados correctos. Los sujetos estarían pasando por alto la probabilidad a priori de sufrir la enfermedad siendo uno de los sesgos más característicos en la estimación de probabilidades condicionales.
Los grupos que se compararon diferían exclusivamente en que en el grupo experimental la redacción del problema se acompañaba del diagrama que representa la figura 6.6.A y el porcentaje de respuestas correctas ascendió de 20% a 48%. La gráfica de los conjuntos anidados redujo de forma sustancial el sesgo observado en la condición control, a pesar de que el problema se formuló en términos de probabilidades. Los diagramas hacen explícito que las posibilidades de que una persona dé positivo en la prueba (tenga síntoma) es un subconjunto de todas las posibilidades y que las posibilidades de padecer la enfermedad es, a la vez, un subconjunto de las posibilidades de dar positivo en la prueba. La representación de las relaciones inclusivas de las categorías nos ayuda a inferir la respuesta correcta: del total de individuos que da positivo en la prueba, 51, 1 padecerá la enfermedad : ?/?? ? ?%
Sloman y cols. (2003) demostraron que el hecho de añadir la categoría de “falsos negativos”7 al problema incrementaba significativamente la dificultad, tanto en términos de probabilidad como de frecuencias. La nueva categoría no era relevante y no altera el valor del resultado, pero incrementa significativamente la complejidad. La nueva categoría supone la representación de un modelo mental adicional que aumenta la “carga” en la memoria de trabajo y dificulta la aplicación del principio del subconjunto para alcanzar la solución correcta del problema. Se intenta minimizar la carga de la memoria de trabajo representando de forma explícita sólo aquellos casos en los que las premisas son verdaderas y se pasan por alto los casos en que son falsas. Johnson-Laird y Savary (1996) demostraron que, razonando sobre probabilidades relativas, la mayor parte de los sujetos alcanzaban conclusiones imposibles cuando no consideraban los casos en que las premisas son falsas. Describimos de forma abreviada uno de los problemas presentados a los participantes en el Experimento 1.
- Solo una afirmación es correcta sobre una mano de cartas de póker:
- Hay un Rey o un As, o ambas.
- Hay una Reina o un As, o ambas.
- ¿Qué es más probable, el Rey o el As?
La respuesta mayoritaria de los sujetos es el “As” y se justifica porque el “As” aparece en una proporción superior de modelos mentales. La respuesta no es correcta. El enunciado es planteado como disyuntiva (X o Y, pero no ambas), Por tanto, no pueden ser ciertas las premisas una y dos. Nunca el “As” podría ser más probable que el “REY”. Cuando los casos falsos se tienen en cuenta y no se contempla la equiprobabilidad de los modelos mentales, la respuesta correcta emerge con facilidad en la representación mental del sujeto. Cuando la basamos en la menor información explícita para evitar saturar nuestra limitada capacidad de procesamiento, podemos llegar a conclusiones ilusorias sobre lo que es más probable. El exceso de confianza subjetiva emitida revela modalidades de ilusiones cognitivas.

El supuesto teórico de” Subaditividad” en el razonamiento probabilístico de la Teoría del apoyo permite explicar la violación de la regla de disyunción (derivada del axioma 3 de la Teoría de la probabilidad) y, de la regla de conjunción (derivada del axioma 4), que se producen como consecuencia de la aplicación de los heurísticos de accesibilidad y representatividad, respectivamente. Los supuestos teóricos de la Teoría de los modelos mentales permiten explicar las dificultades en la representación mental de las relaciones inclusivas relevantes para resolver correctamente la inferencia bayesiana como consecuencia de las limitaciones en la memoria de trabajo. En uno y otro caso, los sesgos sistemáticos observados son el resultado de la violación de los principios de la lógica inclusiva en el modelo normativo de la Teoría de la probabilidad.

JUICIO PROBABILÍSTICO Y CALIBRACIÓN
La calibración se define como el grado de precisión o ajuste entre el juicio probabilístico sobre la confianza en el propio rendimiento y la eficacia objetiva avalada por los datos de la ejecución. Uno de los hallazgos más robustos de esta línea de investigación es el denominado “efecto de exceso de confianza” (sobre-confianza), y se traduce en el hecho de que las personas tenemos más confianza en la eficacia de nuestro rendimiento de lo que avalan los datos objetivos. El sesgo no se limita a los estudios de laboratorio pues se observa también consistentemente en el ámbito profesional. Un segundo efecto estable y consistente sobre la calibración es “efecto fácil-difícil” que constata que el grado de sobre-confianza aumenta con el grado de dificultad de las preguntas.
Enfoques teóricos
El enfoque de los Modelos Mentales Probabilísticos (MMP)
Gigerenzer, Hoffrage y Kleinbölting (1991), proponen un marco integrador que permite explicar el “efecto de exceso de confianza” y el “efecto difícil-fácil”. La tarea prototípica en juicios de confianza incluye preguntas de cultura general con dos alternativas de respuesta, p. ej., “¿Quién nació primero?”: a) Mijaíl Bakunin o b) Karl Marx, o «¿Cuándo se consiguió el sufragio femenino en España?»: a) antes de 1931 o b) después de 1978. El desajuste en la calibración no es una característica intrínseca del juicio humano, sin la consecuencia de la utilización de tareas con escasa validez ecológica. Un modelo mental probabilístico (MMP) es un procedimiento inductivo que se utiliza cuando el conocimiento es limitado y permite realizar inferencias rápidas. La clave conceptual es que un MMP estará adaptado si permiten conectar la estructura específica de la tarea con una estructura de probabilidad en una clase de referencia del ambiente natural del sujeto, almacenada en su memoria de largo plazo. Imaginemos que formulamos: ¿Qué ciudad tiene más habitantes?: a)Xixón o b) A Coruña. La pregunta permite generar una clase de referencia representativa extraída del entorno natural del sujeto, que podría ser “ciudades españolas con una población superior a 200.000 habitantes.
Un MMP para una tarea determinada integra una clase de referencia, en el ejemplo “ciudades españolas con más de 200000 habitantes”, una variable criterio sería “número de habitantes”, y claves probabilísticas que varían en su grado de validez. La MMP asume que las inferencias sobre preguntas inciertas o desconocidas se basan en estas claves probabilísticas, que se generan, se evalúan y se activan para dar la respuesta. En el ejemplo se podían dar: a) tener o no equipo de fútbol, b) ser capital o no de una comunidad autónoma c) tener o no Universidad d) ser ciudad o no industrial, … Si las ciudades a y b tuvieran ambas equipo de fútbol, esta clave no sería válida pues no ayuda a responder la pregunta. La teoría asume que el orden en que se generan las claves refleja una jerarquía de acuerdo con su grado de validez.
Gigerenzer, Hoffrage y Kleinbölting (1991) pusieron a prueba la teoría con el siguiente experimento:
- Se formularon 2 tipos de preguntas:
- Preguntas Representativas. Se utilizó como clase de referencia el conjunto de ciudades del oeste de Alemania con más de 100.000 habitantes.
- Preguntas Seleccionadas. Preguntas de cultura general, y se sometieron al mismo grupo de sujetos.
- El sujeto debía emitir un juicio de confianza relativo a cada una de sus respuestas, tras contestar a la pregunta; y un juicio de frecuencia que debía emitir después de cada bloque de 50 preguntas, referido al número estimado de respuestas correctas en dicho bloque.
De acuerdo con la teoría de los MMP, el sesgo de sobre-confianza, esperado en los juicios sobre cada pregunta individual de cultura general, debería corregirse y ajustarse a la eficacia objetiva cuando se emite un juicio de frecuencia. El supuesto que justifica esta predicción es que cada bloque de preguntas, consideradas en su conjunto, debería constituir una muestra de la clase de referencia natural “conocimiento de cultura general que he demostrado en pruebas o exámenes previos”.
En relación con los juicios de confianza se observa un sesgo de sobre-confianza que es más acusado cuanto mayor es la eficacia de las respuestas de los sujetos. El sesgo se corrige cuando se utilizan preguntas representativas. La curva de confianza para el grupo de preguntas representativas se asemeja a una curva de regresión para la estimación del porcentaje de aciertos a partir de la confianza asignada, revelando subconfianza en la parte izquierda, sobre-confianza en la derecha y cero sobre-confianza como promedio. La media de las diferencias no difiere significativamente de 0 por lo que es un juicio bien calibrado. ¿Se corrige el sesgo observado cuando el juicio de confianza se refiere a la frecuencia de aciertos en una muestra representativa de preguntas seleccionadas? La respuesta es afirmativa. La diferencia media entre la frecuencia estimada de respuestas correctas en cada bloque de preguntas seleccionadas y la frecuencia real no difirió significativamente de 0.
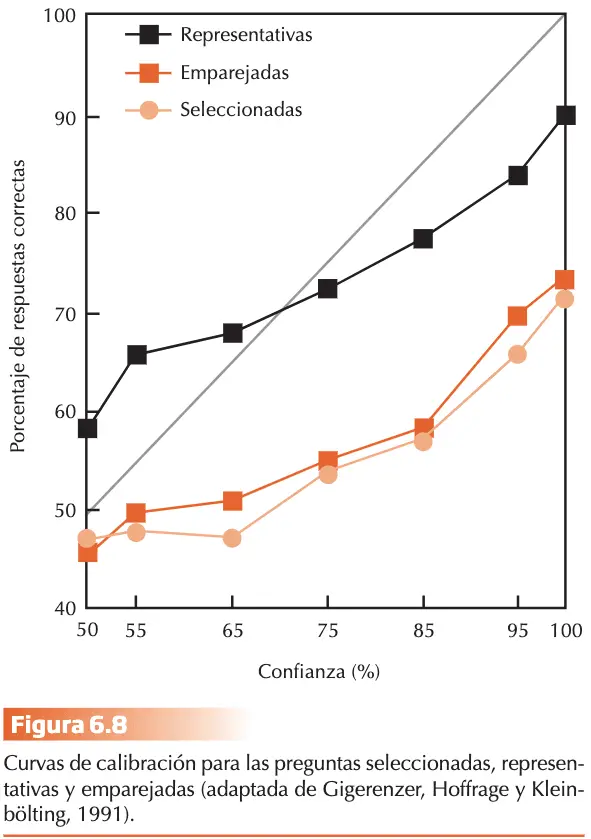
De acuerdo con los autores de los MMP los resultados apoyan la teoría como modelo integrador de resultados empíricos, ésta requiere un mayor desarrollo para responder a determinadas cuestiones que no quedan resueltas con claridad, p. ej., los aspectos a delimitar aluden fundamentalmente a la selección de la clave probabilística que se activa, a si el orden en que se activan las claves se ajusta siempre a su jerarquía de acuerdo con su validez y a las condiciones que determinan que las claves probabilísticas se sustituyan o se integren de forma múltiple para decidir la respuesta. Los autores abordan la respuesta a algunas de estas preguntas en trabajos posteriores. Gigerenzer y Goldstein (1996) formulan el algoritmo básico “Take The Best” (elige el mejor) TTB, que constituye un marco conceptual de la teoría MMP.
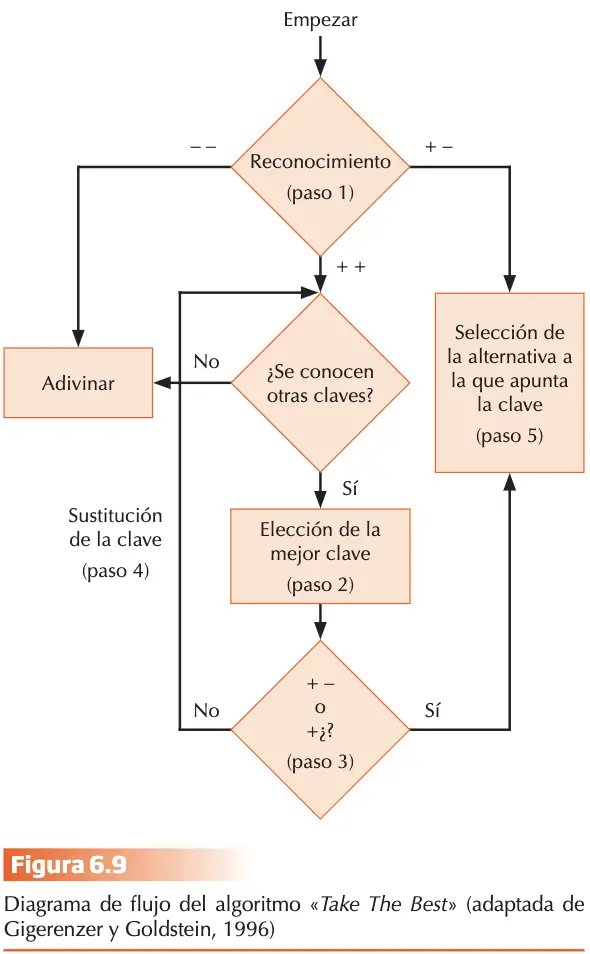
El algoritmo representa un diagrama de flujo en 5 principios para claves binarias:
- Principio de reconocimiento. El reconocimiento de un objeto constituye un predictor de la variable. Si una persona debe decidir cuál de las dos ciudades “a” y “d” tiene más habitantes, la inferencia será la ciudad “a” porque no ha oído hablar de la otra ciudad.
- Búsqueda de claves con validez. Se recuperan de la memoria las claves y sus valores en un orden jerárquico de acuerdo con su grado de validez. La validez ecológica de una clave es la frecuencia relativa con la que predice correctamente el resultado. P. eje., comparando dos ciudades, el 87% de los casos la ciudad que tiene equipo de fútbol que juegue en 1ª Divisón tiene más habitantes, la validez ecológica de la clave es del 0.87.
- Regla de discriminación. Una clave discrimina entre dos objetos si uno de ellos tiene un valor positivo en la clave y el otro no lo tiene.
- Principio de sustitución de la clave. Como se observa en el diagrama de flujo de la figura 6.9, si la clave discrimina, se para la búsqueda de nuevas claves. Si la clave no discrimina se vuelve al paso 2 y se continua la búsqueda hasta que se encuentra la clave que discrimina.
- Regla de maximización para la elección. Se elige el objeto con valor positivo en la clave. El algoritmo TTB es un procedimiento no compensatorio, sólo la clave que mejor discrimina determina la inferencia, sin que la combinación de valores de claves diferentes ni la integración de información puedan contrarrestar la elección basada en la clave con mayor validez.
El algoritmo “elige el mejor” TTB se enmarca dentro de un modelo de racionalidad ecológica que permite explicar cómo el sesgo de sobre-confianza se corrige cuando el participante realiza la inferencia sobre objetos de su entorno natural, que le permiten seleccionar claves probabilísticas con suficiente validez en relación a una variable derivada de la clase de referencia. Una clave probabilística válida es aquella capaz de predecir la inferencia adecuada.
El modelo “fuerza-peso” de la confianza en la evidencia.
Los resultados reflejaban que el sesgo de sobreconfianza no podía reducirse solo al nivel de dificultad. El nivel de eficacia en las respuestas para las variables “voto” y “educación” fue muy similar y cercana al azar, y sin embargo, el sesgo de sobre-confianza fue significativamente superior en la variable de “educación”, respondiendo ello al efecto llamado ilusión de la validez. El estereotipo americano está más unido a la educación que a la participación electoral. P. ej., se considera que el nivel educativo es superior en un estado, en función del número de universidades famosas o eventos culturales que celebran.
Griffin y Tversky (1992) replicaron el estudio de Gigerenzer y cols. Seleccionaron al azar una muestra de 30 pares de estados norteamericanos y pidieron a los sujetos que eligieran qué estado era superior en 3 atributos:
- Número de habitantes.
- Tasa de participación en el voto.
- Tasa de graduados en bachillerato.
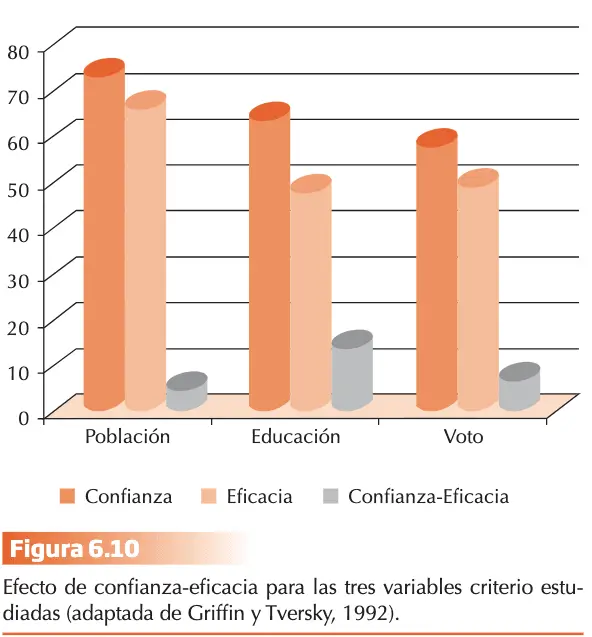
Los resultados delimitan dos variables conceptualmente importantes que intentan explicar sobre las claves que se recuperan a la hora de emitir un juicio probabilístico. La evidencia disponible para emitir un juicio intuitivo se interpreta de acuerdo con 2 coordenadas: la “fuerza” o saliencia de la evidencia y su “peso” o validez predictiva. La Teoría estadística y el cálculo probabilístico prescriben reglas que combinan con precisión fuerza y peso o validez, en cambio el juicio humano no combina ambos factores, lo que produce sesgos y errores de calibración.
Imaginemos que debemos juzgar la probabilidad con la que una persona será contratada a partir de una carta de recomendación escrita en términos cálidos y enfatizando en sus cualidades positivas. En general, las personas focalizamos en la fuerza o carácter extremo del contenido de la carta y tendemos a predecir un resultado favorable al candidato, sin atender de forma suficiente al peso o validez predictiva de la carta: la credibilidad de quien la escribe, tendemos a pasar por alto el tamaño de la muestra; es decir, la frecuencia con la que la persona que escribe la carta lo hace en términos cordiales y positivos, con independencia de las características específicas del candidato. El modelo teórico del juicio probabilístico que integra esta dicotomía predice sobre-confianza cuando la fuerza es elevada y el peso es bajo y sub-confianza cuando la fuerza es baja y el peso es elevado. El hecho de que la fuerza de la evidencia tienda a dominar su peso responde a que el sujeto se focal iza inicialmente en la impresión que le produce la evidencia (la calidez de la carta) para después ajustar el juicio de acuerdo con su conocimiento de su validez (la fiabilidad del que la escribe). El juicio combina el anclaje en la fuerza de la impresión, basado en este ejemplo en la representatividad de la evidencia, con un proceso de ajuste que tiene en cuenta el valor predictivo de la evidencia, pero que resulta insuficiente.
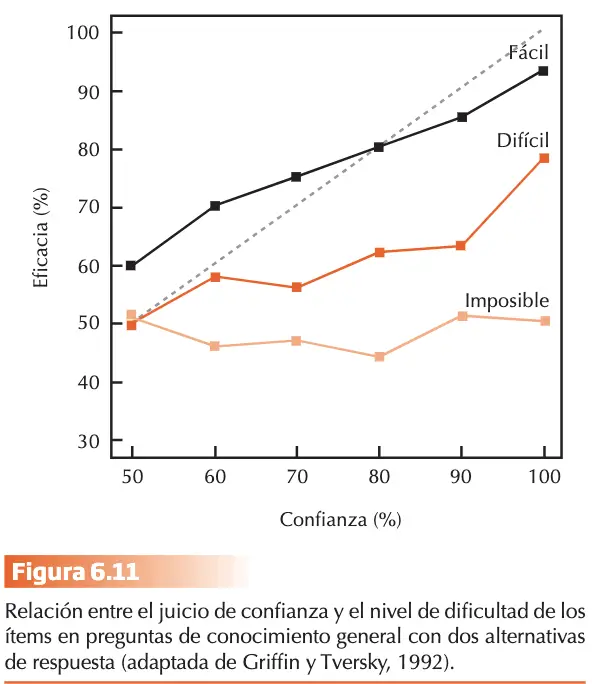
El análisis precedente sugiere que las personas basamos la confianza en nuestro rendimiento, en la impresión sobre los resultados sin observar suficientemente la calidad de los datos. Lichtenstein y Fischhoff (1977) demuestran en un experimento un efecto de sub-confianza (un rendimiento objetivo superior al juicio de confianza) en buena parte del rango cuando los ítems son “fáciles”, un efecto de sobre-confianza (un rendimiento objetivo inferior al juicio de confianza) a lo largo de la mayor parte del rango cuando los ítems son “difíciles” y una sobre-confianza extrema en todo el rango cuando los ítems eran “imposibles” (un ejemplo de ítem “imposible” fue discriminar si un párrafo escrito en inglés había sido escrito por un británico o por un norteamericano).
La calibración en el juicio de los expertos
El juicio probabilístico de los expertos no siempre está bien calibrado. La evidencia indica que también se equivocan, desatienden a las probabilidades a priori de las hipótesis y a la capacidad predictiva del dato, siendo predictores claros de la calibración sesgada. Koehler, Brenner y Griffin (2002), proponen un modelo de calibración adaptado al juicio probabilístico sobre un caso particular, que integra la teoría del apoyo con el modelo de calibración “fuerza-peso” de la confianza en la evidencia.
Koehler y colaboradores (2002) analizaron los datos de nueve investigaciones, que se agrupan en tres categorías. Un grupo de médicos realizó el estudio clínico individual de distintos pacientes que padecían “tos aguda” persistente. Cada paciente era examinado por un solo médico y este rellenaba una lista de síntomas estandarizada. Luego se pedía al médico que estimara la probabilidad de que el paciente tuviera neumonía en una escala de 0 a 100 (sin conocimiento de la radiografía) La “tos aguda y persistente” era el dato y “padecer neumonía” la hipótesis focal. La capacidad predictiva del dato respecto a la hipótesis focal constituye un indicador de la calidad o el peso de la evidencia. El parámetro alfa constituía un dato objetivo y su valor aumenta en relación directa con la capacidad predictiva del dato respecto a la hipótesis focal, frente a otras hipótesis alternativas.
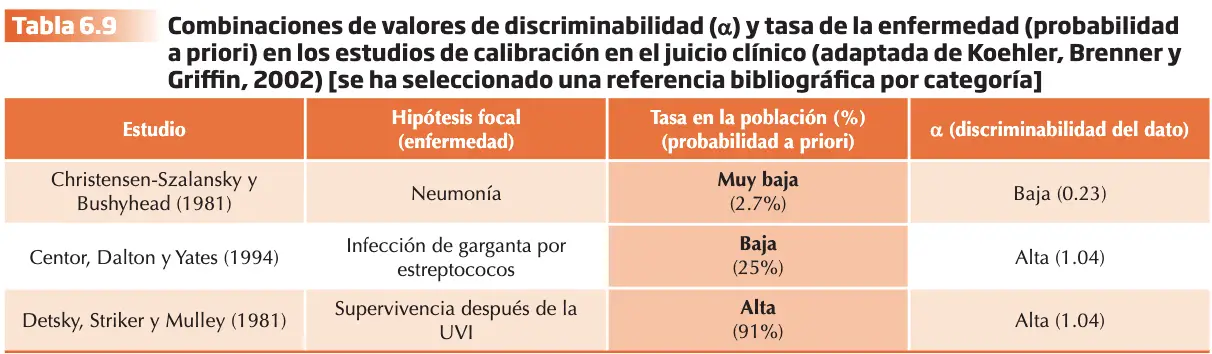
El juicio de los médicos muestra una marcada sub-confianza cuando tanto la probabilidad a priori como la discriminabilidad son elevadas, una ligera sobre-confianza cuando la probabilidad a priori es baja y la discriminabilidad es alta, y una sobre-confianza extrema cuando la probabilidad a priori es muy baja y la discriminabilidad es baja.
Koehler y cols. (2002) interpretan que la “impresión” que causa el síntoma cuando el médico se enfrenta a un caso particular se ve reforzada por la accesibilidad de la fuente de información: el carácter vívido de la experiencia personal y la proximidad al paciente. La “saliencia” del síntoma parece variar en relación inversa con la tasa de la enfermedad en la población. Cuanto más atípica resulta la enfermedad, mayor relevancia adquiere el síntoma y esta relevancia facilita la recuperación de la memoria de información coherente con la evidencia, que resulta de mayor medida disponible. La disponibilidad de síntomas coherentes con la hipótesis focal contribuye a su proceso de “desempaquetado” en sus síntomas componentes, incrementando así su probabilidad subjetiva. El sesgo en la focalización inicial del juicio a favor de la hipótesis focal respecto a las hipótesis alternativas, restará eficacia al proceso de ajuste final, que no considerará de forma suficiente la discriminabilidad objetiva del síntoma: su validez predictiva real de la enfermedad.
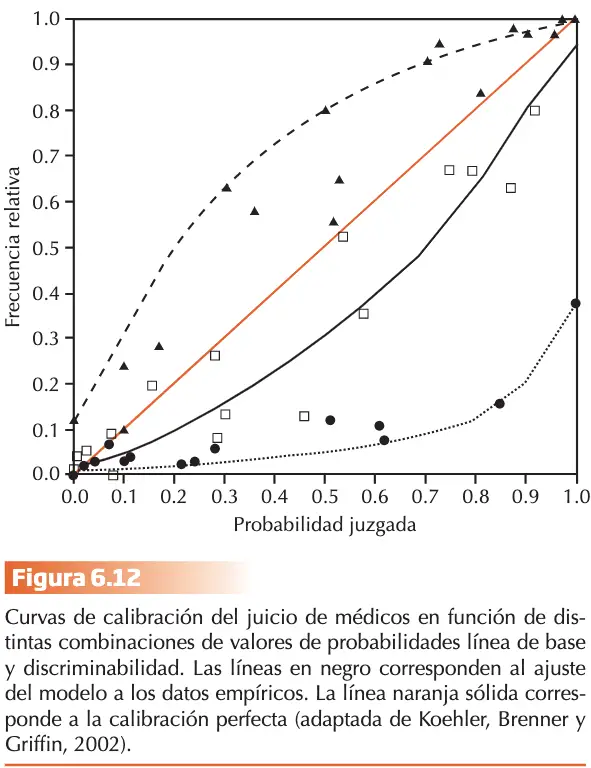
Esta combinación de fuerza (impresión) y peso (validez predictiva) de la evidencia (tos aguda y persistente) respecto a la hipótesis focal (neumonía) se ajusta con bastante exactitud al marco teórico de Griffin y Tversky (1992). La combinación de fuerza alta (tasa muy baja) y peso bajo (discriminabilidad baja) produce sobreconfianza extrema (línea negra discontinua de puntos), mientras que la combinación de fuerza baja (tasa alta) y peso alto (discriminabilidad alta) produce sub-confianza (línea negra discontinua de rayas). Cuando la fuerza tiende a ser alta pero moderada y el peso es elevado la calibración es bastante ajustada (línea negra sólida), si bien tiende a la sobre-confianza pero no de forma significativa.
SESGO PREDICTIVO Y SESGO RETROSPECTIVO
La disponibilidad de la evidencia nos hace sobrevalorar la fuera de la evidencia sin que atendamos suficientemente a la validez de los datos disponibles. El sesgo de sobre-confianza es incluso más acusado en el caso de los expertos por su mayor resistencia a admitir que se han equivocado. ¿A qué obedece esta persistencia en las creencias? Daniel Kahneman (2011) denomina a este sesgo cognitivo “ilusión de validez”. En el caso de la ilusión perceptiva, cuando la persona es advertida de que no puede confiar en lo que percibe y se le hace ver que ambas líneas son de igual magnitud, corrige su ilusión perceptiva e informa correctamente de lo que ahora es una creencia basada en la información objetiva. En contraste con la facilidad con la que corregimos este error perceptivo, la constatación de nuestros errores de calibración en los juicios predictivos puede contribuir a que aceptemos el hecho intelectualmente, pero es poco probable que produzca un impacto real sobre nuestros sentimientos y modifique acciones futuras. La confianza se sustenta en los que denomina la falacia narrativa, basada en el intento continuo de buscar un sentido al mundo que nos rodea y una coherencia en los hechos que se suceden.
El sesgo retrospectivo es la otra cara de la moneda de la “ilusión de validez”. La ilusión de validez nos hace confiar en exceso en nuestros juicios predictivos si son coherentes con la evidencia presente, mientras que el sesgo retrospectivo revisa y reestructura nuestra concepción sobre un hecho del pasado si la evidencia disponible la contradice. Este sesgo es extremadamente robusto demostrado a lo largo de todas las etapas evolutivas de la vida.
Blank y fischer (2000), realizaron el experimento en el cual los participantes predecirían los porcentajes de voto que obtendrían los distintos partidos políticos en las elecciones y recordar las predicciones después de las elecciones. Los participantes recordaron haber estimado un porcentaje de voto que difería en un punto del porcentaje real, desviándose de forma significativa de sus predicciones iniciales. Se les preguntó si el resultado les sorprendía. La mitad no se sorprendió afirmando que los resultados coincidían con su predicción personal. El resto afirmaron que los resultados no podían ser de otra manera y ofrecían distintas razones que justificaban la necesidad del resultado. Los tres componentes del sesgo retrospectivo identificados inicialmente por Fischhoff y cols.:
- Las impresiones de necesidad. Reflejan el grado en que los resultados de un acontecimiento se perciben como determinados casualmente. Se explica porque las personas elaboramos antecedentes consistentes con el resultado de forma que parezca en mayor medida predeterminado.
- Las impresiones de predictibilidad. Asumen las percepciones y juicios coherentes con el hecho de que los resultados podrían haberse anticipado. Efecto de “siempre supe que iba a ocurrir”. La predictibilidad implica consideraciones metacognitivas que presuponen que el resultado podría haberse anticipado en algún momento.
- Las distorsiones de la memoria. Revelan el recuerdo erróneo de que sus predicciones estuvieron muy cerca de lo que de hecho lo estuvieron. Estas distorsiones están gobernadas por procesos de memoria que se concretan en el anclaje en el resultado y la reconstrucción de la predicción inicial.
Blank, Nestler, van Collani y Fischer (2008) definen los procesos psicológicos que subyacen a cada uno de estos componentes. En el caso de la atribución causal las personas elaboramos antecedentes consistentes con el resultado de forma que parezca en mayor medida predeterminado. La impresión de predictibilidad implica consideraciones metacognitivas que presuponen que el resultado podría haberse anticipado en algún momento. Finalmente, las distorsiones en el recuerdo están gobernadas por procesos de memoria que se concretan en el anclaje en el resultado y la reconstrucción de la predicción inicial. El denominador común no dista de ser el resultado de la construcción narrativa basada en la búsqueda de coherencia.


Videoclases
Entrevista a Pilar Sánchez Balmaseda
Razonamiento probabilístico 1/3
Razonamiento probabilístico 2/3
Razonamiento probabilístico 3/3
{kind=link}
REFERENCIAS
•RESUMEN M. GORETTI GONZÁLEZ
•GONZÁLEZ LABRA, M., SÁNCHEZ BALMASEDA, P., & ORENES CASANOVA, I. (2019). PSICOLOGÍA DEL PENSAMIENTO. MADRID: SANZ Y TORRES.